Gene set testing for Illumina HumanMethylation Arrays
Evaluating the functionality and performance of GOregion
Jovana Maksimovic, Alicia Oshlack and Belinda Phipson
April 20, 2021
Last updated: 2021-04-20
Checks: 7 0
Knit directory: methyl-geneset-testing/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it's best to always run the code in an empty environment.
The command set.seed(20200302) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 9d23572. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/figures.nb.html
Ignored: code/.DS_Store
Ignored: code/.Rhistory
Ignored: code/.job/
Ignored: code/old/
Ignored: data/.DS_Store
Ignored: data/annotations/
Ignored: data/cache-intermediates/
Ignored: data/cache-region/
Ignored: data/cache-rnaseq/
Ignored: data/cache-runtime/
Ignored: data/datasets/.DS_Store
Ignored: data/datasets/GSE110554-data.RData
Ignored: data/datasets/GSE120854/
Ignored: data/datasets/GSE120854_RAW.tar
Ignored: data/datasets/GSE135446-data.RData
Ignored: data/datasets/GSE135446/
Ignored: data/datasets/GSE135446_RAW.tar
Ignored: data/datasets/GSE45459-data.RData
Ignored: data/datasets/GSE45459_Matrix_signal_intensities.txt
Ignored: data/datasets/GSE45460/
Ignored: data/datasets/GSE45460_RAW.tar
Ignored: data/datasets/GSE95460_RAW.tar
Ignored: data/datasets/GSE95460_RAW/
Ignored: data/datasets/GSE95462-data.RData
Ignored: data/datasets/GSE95462/
Ignored: data/datasets/GSE95462_RAW/
Ignored: data/datasets/SRP100803/
Ignored: data/datasets/SRP125125/.DS_Store
Ignored: data/datasets/SRP125125/SRR6298*/
Ignored: data/datasets/SRP125125/SRR_Acc_List.txt
Ignored: data/datasets/SRP125125/SRR_Acc_List_Full.txt
Ignored: data/datasets/SRP125125/SraRunTable.txt
Ignored: data/datasets/SRP125125/multiqc_data/
Ignored: data/datasets/SRP125125/multiqc_report.html
Ignored: data/datasets/SRP125125/quants/
Ignored: data/datasets/SRP166862/
Ignored: data/datasets/SRP217468/
Ignored: data/datasets/TCGA.BRCA.rds
Ignored: data/datasets/TCGA.KIRC.rds
Ignored: data/misc/
Ignored: output/.DS_Store
Ignored: output/FDR-analysis/
Ignored: output/compare-methods/
Ignored: output/figures/
Ignored: output/methylgsa-params/
Ignored: output/outputs.tar.gz
Ignored: output/random-cpg-sims/
Untracked files:
Untracked: analysis/old/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/07_regionAnalysisBcells.Rmd) and HTML (docs/07_regionAnalysisBcells.html) files. If you've configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 9d23572 | JovMaksimovic | 2021-04-20 | wflow_publish(rownames(stat\(status)[stat\)status$modified == TRUE]) |
| html | 4c57176 | JovMaksimovic | 2021-04-13 | Build site. |
| Rmd | 2a8ac36 | JovMaksimovic | 2021-04-13 | Changed RNAseq to Array for B-cell data analyses |
| Rmd | 697c330 | JovMaksimovic | 2021-04-12 | Updated figure numbering and labels |
| html | 2cc0866 | JovMaksimovic | 2021-04-06 | Build site. |
| html | f14b742 | JovMaksimovic | 2021-04-06 | Build site. |
| Rmd | ea1abcf | JovMaksimovic | 2021-04-06 | wflow_publish(c("analysis/07_regionAnalysisBcells.Rmd")) |
| html | a9a3a86 | JovMaksimovic | 2021-04-06 | Build site. |
| Rmd | 9843157 | JovMaksimovic | 2021-04-06 | wflow_publish(c("analysis/index.Rmd", "analysis/07_regionAnalysisBcells.Rmd", |
library(here)
library(ChAMP)
library(minfi)
library(paletteer)
library(limma)
library(BiocParallel)
library(reshape2)
library(DMRcate)
library(missMethyl)
library(ggplot2)
library(glue)
library(UpSetR)
library(dplyr)
library(patchwork)
library(tibble)
library(grid)
library(ggupset)
library(ggpubr)
library(TxDb.Hsapiens.UCSC.hg19.knownGene)
source(here("code/utility.R"))Load data
We are using publicly available 450K data GSE45459 generated from developing human B-cells. The data is normalised and filtered (bad probes, multi-mapping probes, SNP probes, sex chromosomes).
# load data
dataFile <- here("data/datasets/GSE45459-data.RData")
if(file.exists(dataFile)){
# load processed data and sample information
load(dataFile)
} else {
raw <- read.delim(here("data/datasets/GSE45459_Matrix_signal_intensities.txt"),
row.names = "ID_REF")
M <- raw[,grepl("Methylated", colnames(raw))]
U <- raw[,grepl("Unmethylated", colnames(raw))]
detP <- raw[,grepl("Pval", colnames(raw))]
targets <- as.data.frame(strsplit2(colnames(detP),"_")[,1:2])
colnames(targets) <- c("ID","Stage")
mSet <- MethylSet(Meth = as.matrix(M), Unmeth = as.matrix(U),
annotation = c(array = "IlluminaHumanMethylation450k",
annotation = "ilmn12.hg19"))
colnames(mSet) <- targets$ID
grRaw <- minfi::mapToGenome(mSet)
#normalise
normGr <- preprocessQuantile(grRaw)
#filter
fltGr <- filterQual(normGr = normGr, detP = detP)
fltGr <- filterProbes(fltGr)
save(detP, normGr, fltGr, targets, file = dataFile)
}Statistical analysis
Compare stages of pre B-cell development. Consider results significant at FDR < 0.05 and delta beta ~ 10% (~ lfc = 0.5).
mVals <- getM(fltGr)
bVals <- getBeta(fltGr)Stage <- factor(targets$Stage)
design <- model.matrix(~0+Stage)
fit <- lmFit(mVals, design)
cont.matrix <- makeContrasts(S1vS2=StageS1-StageS2,
levels=design)
fit2 <- contrasts.fit(fit, cont.matrix)
fit2 <- eBayes(fit2, robust=TRUE, trend=TRUE)
tfit <- treat(fit2, lfc = 0.5)
pval <- 0.05
fitSum <- summary(decideTests(tfit, p.value = pval))
fitSum S1vS2
Down 1083
NotSig 366973
Up 2065Find differentially methylated regions
Identify differentially methylated regions using the DMRcate package.
outDir <- here::here("data/cache-region")
if (!dir.exists(outDir)) dir.create(outDir)
outFile <- here("data/cache-region/dmrcate-GSE45459-results.rds")
if(!file.exists(outFile)){
dmrList <- vector("list", ncol(cont.matrix))
for(i in 1:ncol(cont.matrix)){
cpgAnn <- cpg.annotate("array", mVals, what = "M", arraytype = "450K",
analysis.type = "differential", design = design,
contrasts = TRUE, cont.matrix = cont.matrix,
coef = colnames(fitSum)[i])
dmrList[[i]] <- extractRanges(dmrcate(cpgAnn))
}
names(dmrList) <- colnames(cont.matrix)
saveRDS(dmrList, file = outFile)
} else {
dmrList <- readRDS(outFile)
}
length(dmrList[[1]])[1] 2151GO analysis of DMRs
Run GO analysis on the differentially methylated regions (DMRs) identified using the DMRcate package.
outFile <- here("data/cache-region/dmrcate-GSE45459-go.rds")
anno <- loadAnnotation(arrayType = "450k")
txdb <- TxDb.Hsapiens.UCSC.hg19.knownGene
hg19Genes <- GenomicFeatures::genes(txdb)
dmrGo <- NULL
if(!file.exists(outFile)){
for(i in 1:length(dmrList)){
overlaps <- findOverlaps(hg19Genes, dmrList[[i]],
minoverlap = 1)
sigGenes <- hg19Genes$gene_id[from(overlaps)]
tmp <- topGO(goana(sigGenes, universe = hg19Genes$gene_id),
number = Inf)
tmp <- rownames_to_column(tmp, var = "GO")[, c("GO", "P.DE")]
tmp$method <- "goana"
tmp$contrast <- colnames(cont.matrix)[i]
dmrGo <- bind_rows(dmrGo, tmp)
tmp <- topGSA(goregion(dmrList[[i]], anno = anno,
prior.prob = FALSE, array.type = "450k"),
number = Inf)
tmp <- rownames_to_column(tmp, var = "GO")[, c("GO", "P.DE")]
tmp$method <- "goregion-hgt"
tmp$contrast <- colnames(cont.matrix)[i]
dmrGo <- bind_rows(dmrGo, tmp)
tmp <- topGSA(goregion(dmrList[[i]], anno = anno,
array.type = "450k", plot.bias = FALSE),
number = Inf)
tmp <- rownames_to_column(tmp, var = "GO")[, c("GO", "P.DE")]
tmp$method <- "goregion-gometh"
tmp$contrast <- colnames(cont.matrix)[i]
dmrGo <- bind_rows(dmrGo, tmp)
tmp <- topGSA(gometh(rownames(topTreat(tfit, coef = i, num = 5000)),
anno = anno, array.type = "450k"), number = Inf)
tmp <- rownames_to_column(tmp, var = "GO")[, c("GO", "P.DE")]
tmp$method <- "gometh-probe-top"
tmp$contrast <- colnames(cont.matrix)[i]
dmrGo <- bind_rows(dmrGo, tmp)
tmp <- topGSA(gometh(rownames(topTreat(tfit, coef = i, num = Inf,
p.value = pval)), anno = anno,
array.type = "450k"), number = Inf)
tmp <- rownames_to_column(tmp, var = "GO")[, c("GO", "P.DE")]
tmp$method <- "gometh-probe-fdr"
tmp$contrast <- colnames(cont.matrix)[i]
dmrGo <- bind_rows(dmrGo, tmp)
}
saveRDS(dmrGo, file = outFile)
} else {
dmrGo <- readRDS(outFile)
}Probe bias in DMRs
bDat <- vector("list", length(dmrList))
cpgs <- GRanges(seqnames = anno$chr,
ranges = IRanges(start = anno$pos, end = anno$pos),
strand = anno$strand,
name = anno$Name)
for(i in 1:length(dmrList)){
overlaps <- findOverlaps(cpgs, dmrList[[i]])
dmrCpgs <- cpgs$name[from(overlaps)]
bDat[[i]] <- getBiasDat(dmrCpgs, array.type = "450k",
anno = anno)
}All input CpGs are used for testing.p <- vector("list", length(bDat))
for(i in 1:length(p)){
p[[i]] <- ggplot(bDat[[i]], aes(x = avgbias, y = propDM)) +
geom_point(shape = 1, size = 2) +
geom_smooth() +
labs(x = "No. CpGs per gene (binned)",
y = "Prop. differential methylation") +
theme_minimal() +
theme(panel.grid = element_blank(),
axis.line = element_line(colour = "black"))
}
p[[1]] + labs(title = names(dmrList)[1])`geom_smooth()` using method = 'loess' and formula 'y ~ x'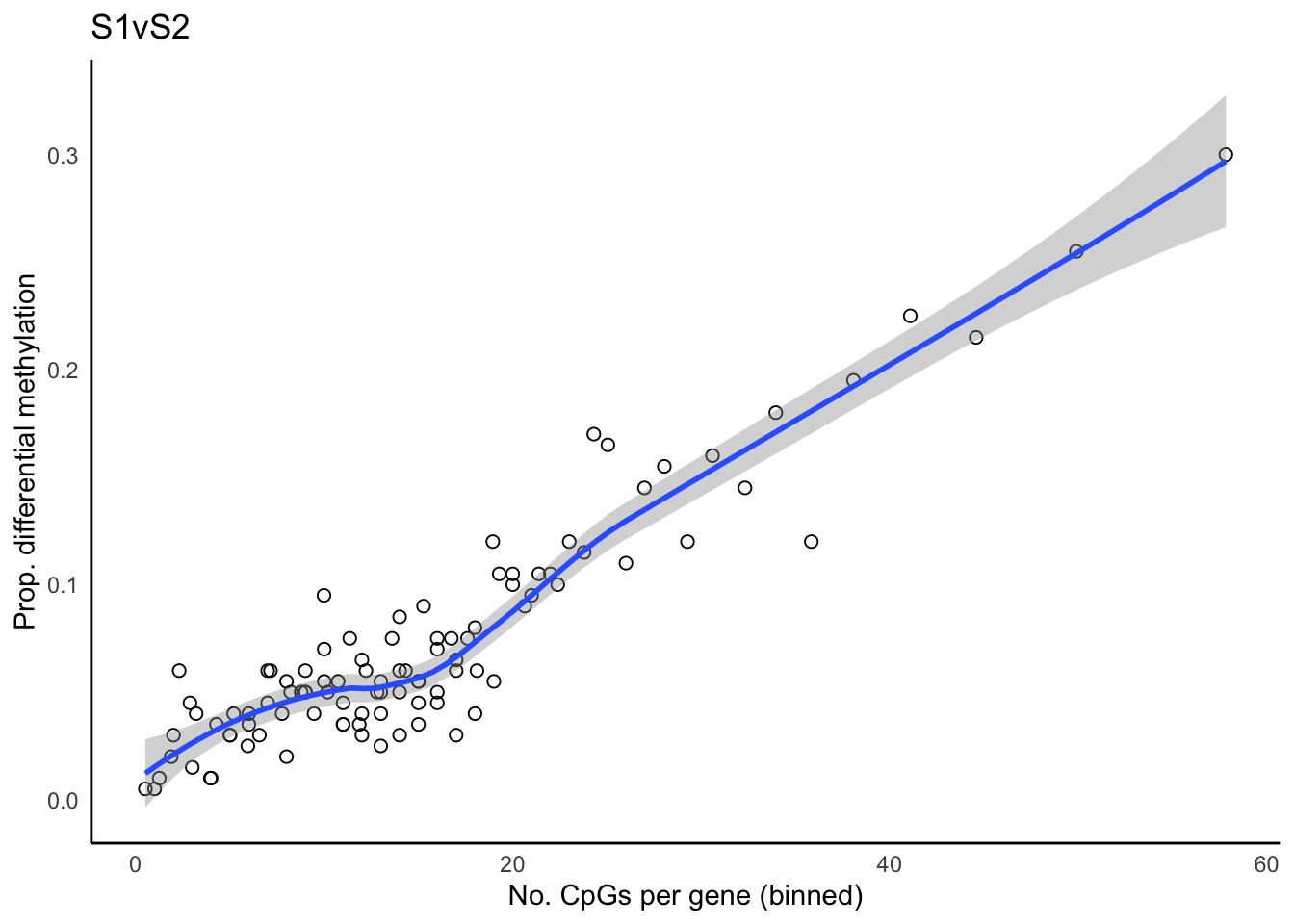
| Version | Author | Date |
|---|---|---|
| 4c57176 | JovMaksimovic | 2021-04-13 |
Save figure for use in manuscript.
fig <- here("output/figures/SFig-14A.rds")
saveRDS(p[[1]], fig, compress = FALSE)Compare GOregion with other approaches
immuneGO <- unique(read.csv(here("data/genesets/GO-immune-system-process.txt"),
stringsAsFactors = FALSE, header = FALSE,
col.names = "GOID"))
rnaseqGO <- readRDS(here("data/cache-rnaseq/RNAseq-GSE45460-GO.rds"))
rnaseqGO %>% group_by(contrast) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 100) -> topGOSets
dmrGo %>% arrange(contrast, method, P.DE) %>%
dplyr::filter(method %in% c("goana", "goregion-gometh")) %>%
mutate(method = unname((dict[method]))) %>%
group_by(contrast, method) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 100) -> dat
p <- vector("list", length(unique(dat$contrast)))
for(i in 1:length(p)){
cont <- sort(unique(dat$contrast))[i]
dat %>% dplyr::filter(contrast == cont) %>%
arrange(method, P.DE) %>%
group_by(method) %>%
mutate(csum = cumsum(GO %in% immuneGO$GOID)) %>%
mutate(truth = "ISP Terms") -> immuneSum
dat %>% dplyr::filter(contrast == cont) %>%
arrange(method, P.DE) %>%
group_by(method) %>%
mutate(csum = cumsum(GO %in% topGOSets$ID[topGOSets$contrast %in%
contrast])) %>%
mutate(truth = "Array Terms") -> rnaseqSum
truthSum <- bind_rows(immuneSum, rnaseqSum)
p[[i]] <- ggplot(truthSum, aes(x = rank, y = csum, colour = method)) +
geom_line() +
facet_wrap(vars(truth)) +
geom_vline(xintercept = 10, linetype = "dotted") +
labs(colour = "Method", x = "Rank",
y = glue("Cumulative no. Array sets")) +
theme(legend.position = "bottom") +
scale_color_manual(values = methodCols) +
ggtitle(cont)
}
p[[1]]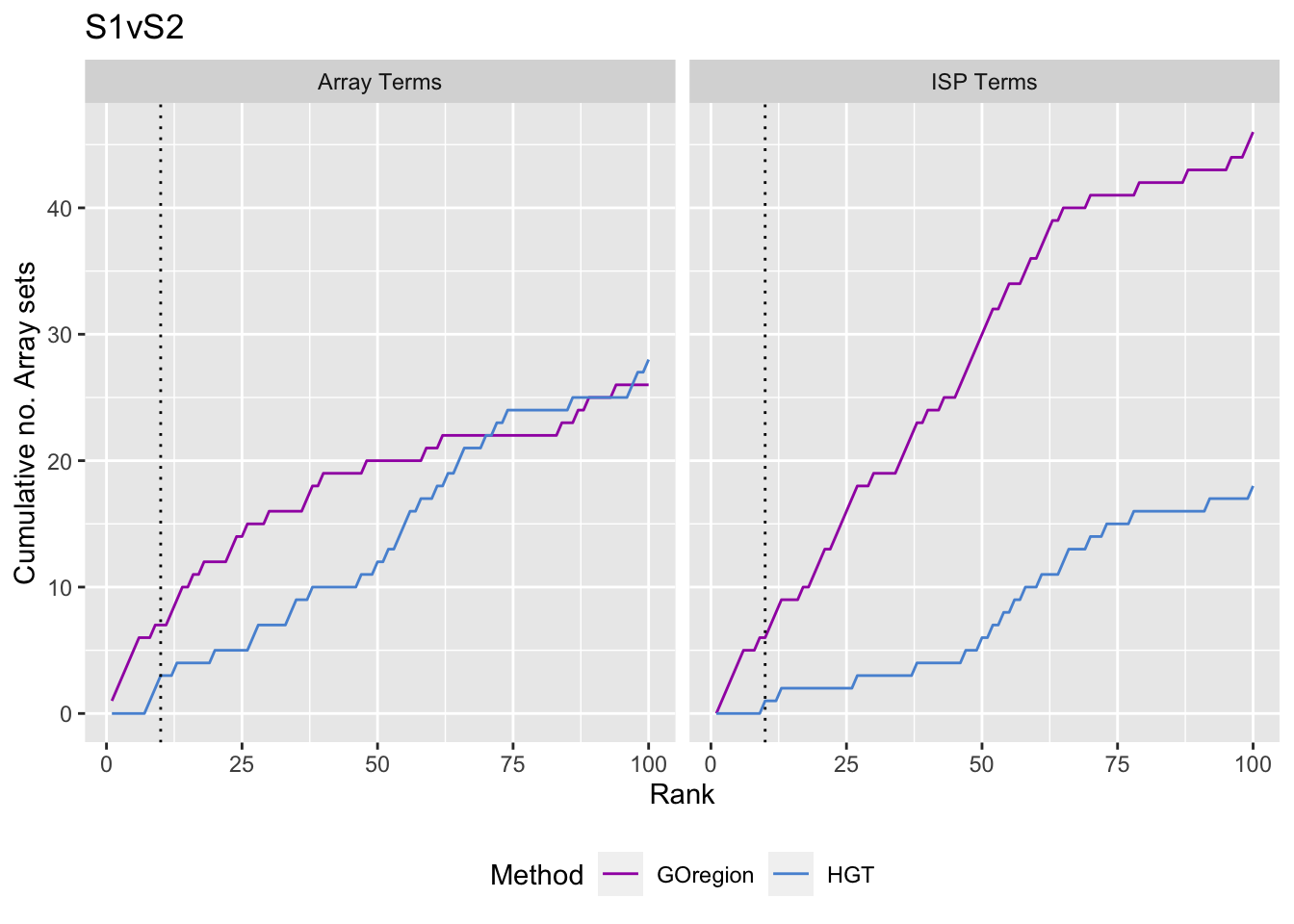
Save figure for use in manuscript.
fig <- here("output/figures/SFig-14B.rds")
saveRDS(p[[1]], fig, compress = FALSE)Examine what the top 10 ranked gene sets are and how many genes they contain.
terms <- missMethyl:::.getGO()$idTable
nGenes <- rownames_to_column(data.frame(n = sapply(missMethyl:::.getGO()$idList,
length)),
var = "ID")
dat %>% arrange(contrast, method, P.DE) %>%
group_by(contrast, method) %>%
mutate(FDR = p.adjust(P.DE, method = "BH")) %>%
dplyr::filter(rank <= 10) %>%
inner_join(terms, by = c("GO" = "GOID")) %>%
inner_join(nGenes, by = c("GO" = "ID")) -> subp <- vector("list", length(unique(sub$contrast)))
truthPal <- scales::hue_pal()(4)
names(truthPal) <- c("Both", "ISP", "Neither", "Array")
for(i in 1:length(p)){
cont <- sort(unique(sub$contrast))[i]
sub %>% dplyr::filter(contrast == cont) %>%
arrange(method, -rank) %>%
ungroup() %>%
mutate(idx = as.factor(1:n())) -> tmp
setLabs <- substr(tmp$TERM, 1, 40)
names(setLabs) <- tmp$idx
tmp %>% mutate(rna = GO %in% topGOSets$ID[topGOSets$contrast %in% cont],
isp = GO %in% immuneGO$GOID,
both = rna + isp,
col = ifelse(both == 2, "Both",
ifelse(both == 1 & rna == 1, "Array",
ifelse(both == 1 & isp == 1,
"ISP", "Neither")))) %>%
mutate(col = factor(col,
levels = c("Both", "ISP", "Array",
"Neither"))) -> tmp
p[[i]] <- ggplot(tmp, aes(x = -log10(FDR), y = idx, colour = col)) +
geom_point(aes(size = n), alpha = 0.7) +
scale_size(limits = c(min(sub$n), max(sub$n))) +
facet_wrap(vars(method), ncol = 2, scales = "free") +
scale_y_discrete(labels = setLabs) +
scale_colour_manual(values = truthPal) +
labs(y = "", size = "No. genes", colour = "In truth set") +
theme(axis.text = element_text(size = 8),
legend.box = "vertical",
legend.position = "bottom",
legend.margin = margin(0, 0, 0, 0, unit = "lines"),
panel.spacing.x = unit(1, "lines")) +
coord_cartesian(xlim = c(-log10(0.99), -log10(10^-80))) +
geom_vline(xintercept = -log10(0.05), linetype = "dashed") +
ggtitle(cont)
}
shift_legend(p[[1]], plot = TRUE, pos = "left")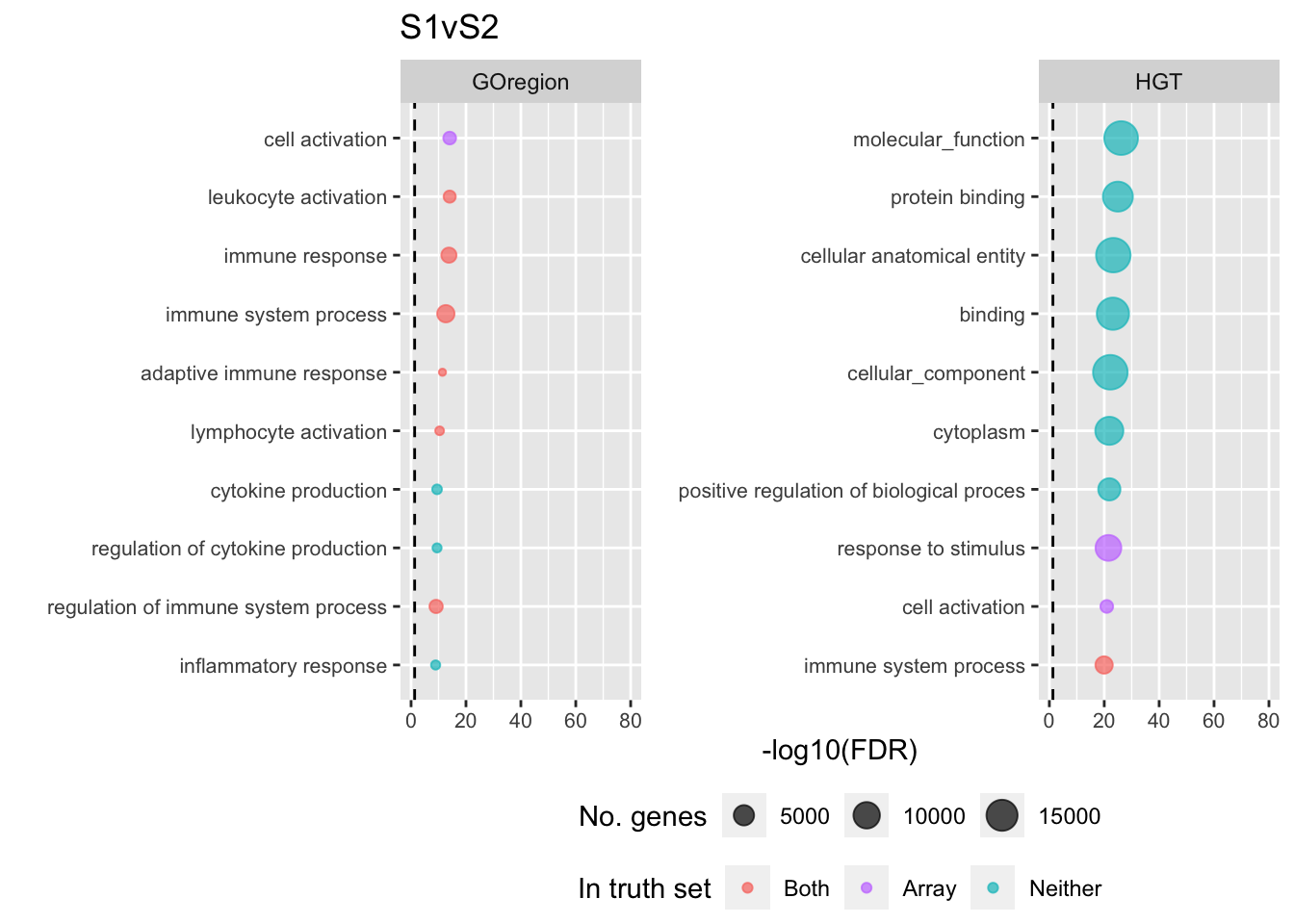
Save figure for use in manuscript.
fig <- here("output/figures/SFig-14C.rds")
saveRDS(p[[1]], fig, compress = FALSE)Compare GOregion with probe-wise analysis
p <- vector("list", length(unique(dat$contrast)))
for(i in 1:length(p)){
cont <- sort(unique(dat$contrast))[i]
dmrGo %>% dplyr::filter(method %in% c("goregion-gometh", "gometh-probe-top",
"gometh-probe-fdr")) %>%
mutate(method = unname((dict[method]))) %>%
arrange(contrast, method, P.DE) %>%
group_by(contrast, method) %>%
mutate(csum = cumsum(GO %in% immuneGO$GOID)) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 100) %>%
mutate(truth = "ISP Terms") -> immuneSum
dmrGo %>% dplyr::filter(method %in% c("goregion-gometh", "gometh-probe-top",
"gometh-probe-fdr")) %>%
mutate(method = unname((dict[method]))) %>%
arrange(contrast, method, P.DE) %>%
group_by(contrast, method) %>%
mutate(csum = cumsum(GO %in% topGOSets$ID[topGOSets$contrast %in%
cont])) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 100) %>%
mutate(truth = "Array Terms") -> rnaseqSum
truthSum <- bind_rows(immuneSum, rnaseqSum)
p[[i]] <- ggplot(truthSum, aes(x = rank, y = csum, colour = method)) +
geom_line() +
facet_wrap(vars(truth)) +
geom_vline(xintercept = 10, linetype = "dotted") +
labs(colour = "Parameters", x = "Rank",
y = glue("Cumulative no. truth sets")) +
theme(legend.position = "right") +
ggtitle(cont) +
scale_color_manual(values = methodCols)
}
p[[1]]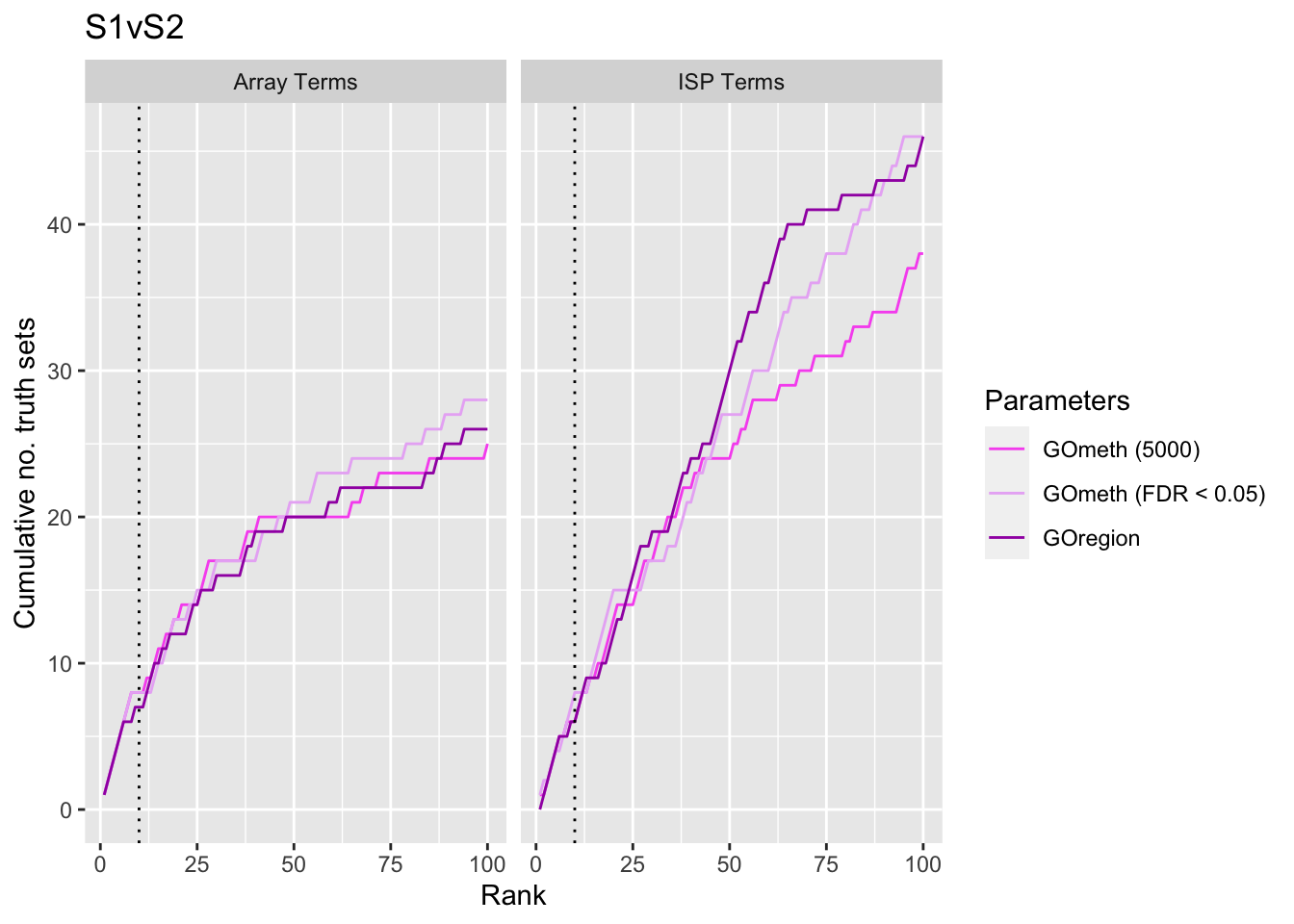
| Version | Author | Date |
|---|---|---|
| 4c57176 | JovMaksimovic | 2021-04-13 |
Save figure for use in manuscript.
fig <- here("output/figures/SFig-15A.rds")
saveRDS(p[[1]], fig, compress = FALSE)Examine what the top 10 ranked gene sets are and how many genes they contain.
terms <- missMethyl:::.getGO()$idTable
nGenes <- rownames_to_column(data.frame(n = sapply(missMethyl:::.getGO()$idList,
length)),
var = "ID")
dmrGo %>% dplyr::filter(method %in% c("goregion-gometh", "gometh-probe-top",
"gometh-probe-fdr")) %>%
mutate(method = unname((dict[method]))) %>%
arrange(contrast, method, P.DE) %>%
group_by(contrast, method) %>%
mutate(FDR = p.adjust(P.DE, method = "BH")) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 10) %>%
inner_join(terms, by = c("GO" = "GOID")) %>%
inner_join(nGenes, by = c("GO" = "ID")) -> subp <- vector("list", length(unique(sub$contrast)))
for(i in 1:length(p)){
cont <- sort(unique(sub$contrast))[i]
sub %>% dplyr::filter(contrast == cont) %>%
arrange(method, -rank) %>%
ungroup() %>%
mutate(idx = as.factor(1:n())) -> tmp
setLabs <- substr(tmp$TERM, 1, 40)
names(setLabs) <- tmp$idx
tmp %>% mutate(rna = GO %in% topGOSets$ID[topGOSets$contrast %in% cont],
isp = GO %in% immuneGO$GOID,
both = rna + isp,
col = ifelse(both == 2, "Both",
ifelse(both == 1 & rna == 1, "Array",
ifelse(both == 1 & isp == 1,
"ISP", "Neither")))) %>%
mutate(col = factor(col,
levels = c("Both", "ISP", "Array",
"Neither"))) -> tmp
p[[i]] <- ggplot(tmp, aes(x = -log10(FDR), y = idx, colour = col)) +
geom_point(aes(size = n), alpha = 0.7) +
scale_size(limits = c(min(sub$n), max(sub$n))) +
facet_wrap(vars(method), ncol = 2, scales = "free") +
scale_y_discrete(labels = setLabs) +
scale_color_manual(values = truthPal) +
labs(y = "", size = "No. genes", colour = "In truth set") +
theme(axis.text = element_text(size = 7),
legend.margin = margin(0, 0, 0, 0, unit = "lines"),
legend.box = "horizontal",
panel.spacing.x = unit(1, "lines")) +
coord_cartesian(xlim = c(-log10(0.99), -log10(10^-80))) +
geom_vline(xintercept = -log10(0.05), linetype = "dashed") +
ggtitle(cont)
}
shift_legend(p[[1]], plot = TRUE, pos = "left")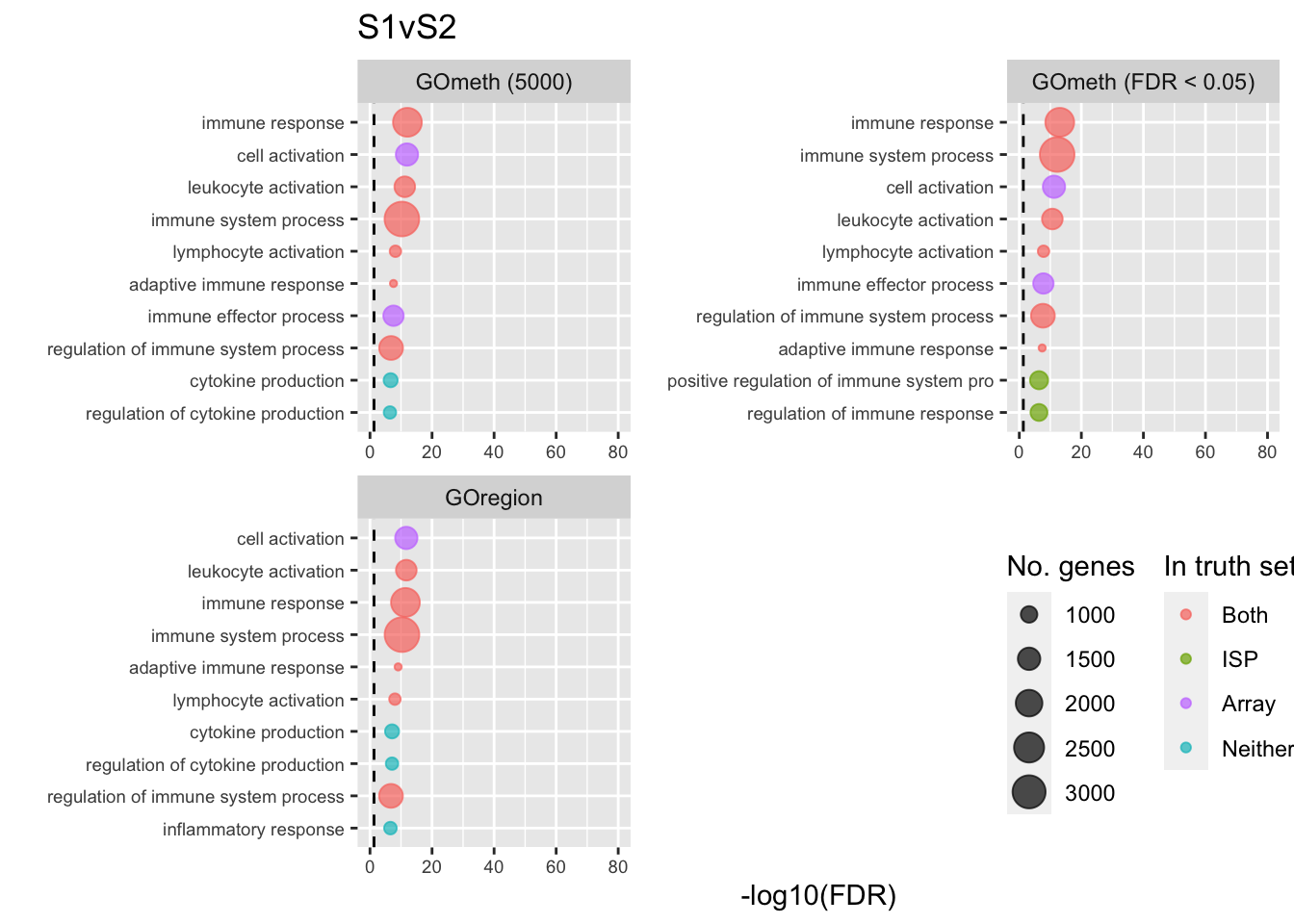
Save figure for use in manuscript.
fig <- here("output/figures/SFig-15B.rds")
saveRDS(p[[1]], fig, compress = FALSE)Compare characteristics of region-wise and probe-wise results
cpgs <- GRanges(seqnames = anno$chr,
ranges = IRanges(start = anno$pos,
end = anno$pos),
strand = anno$strand,
name = anno$Name)
dat <- NULL
for(i in 1:ncol(cont.matrix)){
overlaps <- findOverlaps(cpgs, dmrList[[i]])
tmp <- data.frame(cpgs = cpgs$name[from(overlaps)],
method = "DMRcate",
contrast = colnames(cont.matrix)[i],
stringsAsFactors = FALSE)
dat <- bind_rows(dat, tmp)
tmp <- data.frame(cpgs = rownames(topTreat(tfit, coef = i, num = 5000)),
method = "Top 5000",
contrast = colnames(cont.matrix)[i],
stringsAsFactors = FALSE)
dat <- bind_rows(dat, tmp)
tmp <- data.frame(cpgs = rownames(topTreat(tfit, coef = i, num = Inf,
p.value = pval)),
method = "FDR < 0.05",
contrast = colnames(cont.matrix)[i],
stringsAsFactors = FALSE)
dat <- bind_rows(dat, tmp)
}
dat %>% group_by(contrast, method) %>%
tally() -> sub
selectCols <- c("#ff6b97", "#48bf8e", "#a41415")
names(selectCols) <- unique(dat$method)
ggplot(sub, aes(x = method, y = n, fill = method)) +
geom_bar(stat = "identity", show.legend = FALSE) +
facet_wrap(vars(contrast)) +
labs(y = "No. significant CpGs", x = "Sig. CpGs selected using") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_manual(values = selectCols)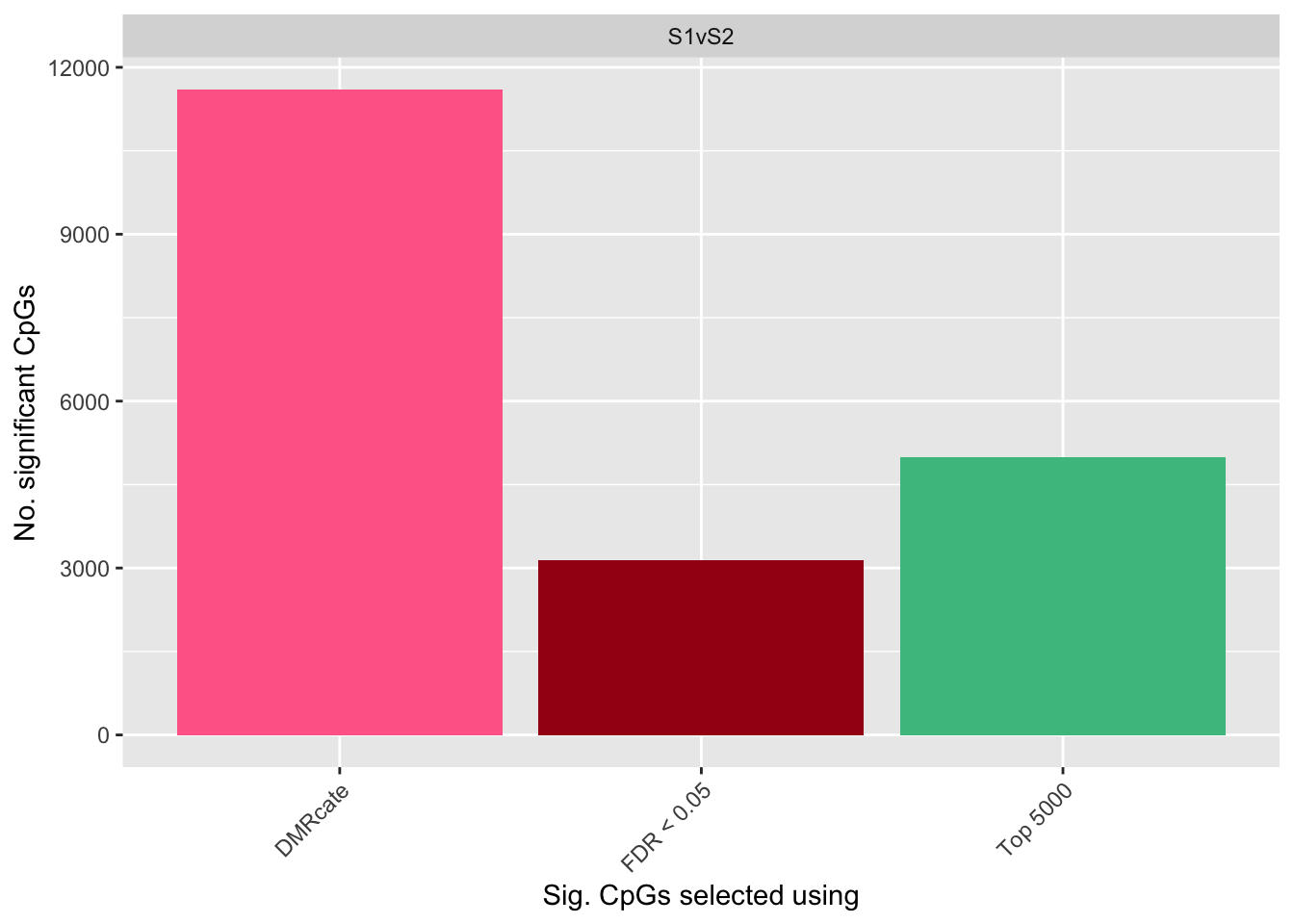
flatAnn <- loadFlatAnnotation(anno)
dat %>% group_by(contrast, method) %>%
inner_join(flatAnn, by = c("cpgs" = "cpg")) %>%
group_by(contrast, method) %>%
dplyr::select(group_cols(), entrezid) %>%
distinct() %>%
tally() -> sub
ggplot(sub, aes(x = method, y = n, fill = method)) +
geom_bar(stat = "identity", show.legend = FALSE) +
facet_wrap(vars(contrast)) +
labs(y = "No. genes with sig. CpGs", x = "Sig. CpGs selected using") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_manual(values = selectCols)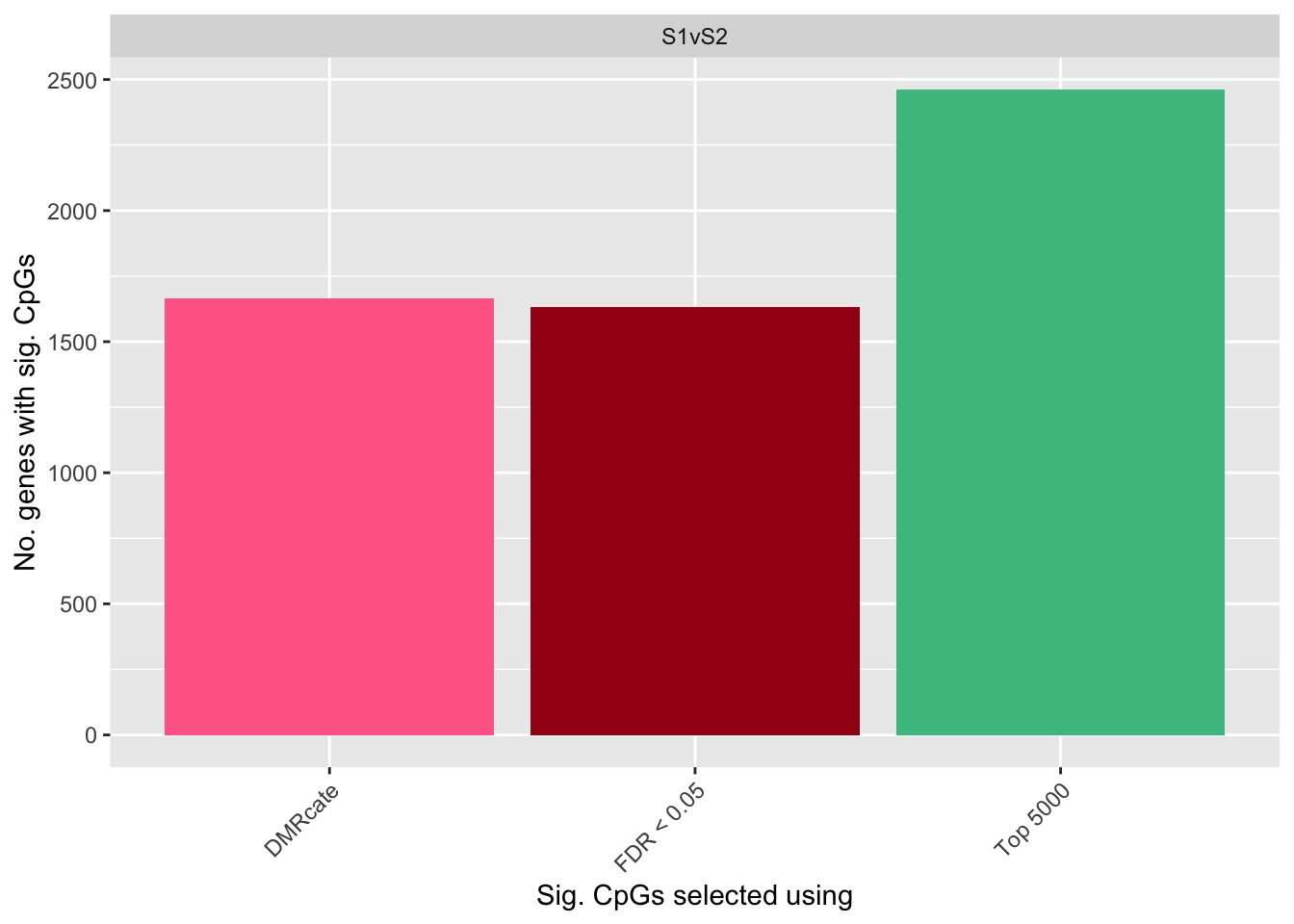
dat %>% group_by(contrast, method) %>%
left_join(flatAnn, by = c("cpgs" = "cpg")) %>%
group_by(contrast, method) %>%
dplyr::select(group_cols(), entrezid, cpgs) %>%
summarise(prop = sum(!is.na(entrezid[!duplicated(cpgs)]))/
length(unique(cpgs))) -> sub`summarise()` has grouped output by 'contrast'. You can override using the `.groups` argument.p <- vector("list", length(unique(sub$contrast)))
for(i in 1:length(p)){
cont <- sort(unique(sub$contrast))[i]
p[[i]] <- ggplot(sub[sub$contrast == cont,],
aes(x = method, y = prop)) +
geom_bar(stat = "identity",
show.legend = FALSE,
fill="black") +
labs(y = "Prop. sig. CpGs mapped to genes",
x = "Sig. CpGs selected using") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_x_discrete(limits = c("FDR < 0.05", "DMRcate", "Top 5000"))
}
p[[1]] + ggtitle(sort(unique(sub$contrast))[1])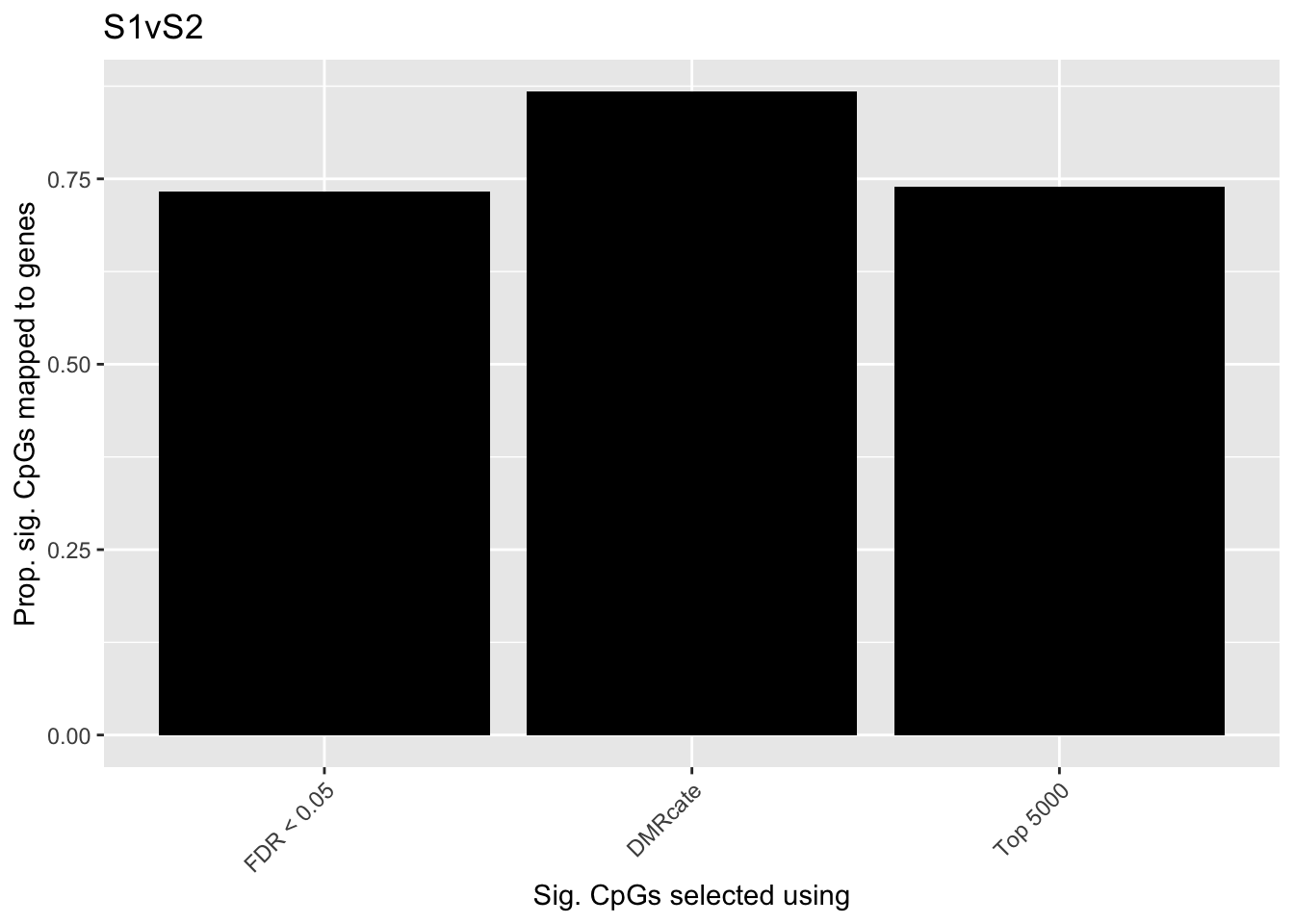
| Version | Author | Date |
|---|---|---|
| 4c57176 | JovMaksimovic | 2021-04-13 |
Save figure for use in manuscript.
fig <- here("output/figures/SFig-14E.rds")
saveRDS(p[[1]], fig, compress = FALSE)dat %>% group_by(contrast, method) %>%
left_join(flatAnn, by = c("cpgs" = "cpg")) %>%
group_by(contrast, method) %>%
dplyr::select(group_cols(), group, cpgs) %>%
group_by(contrast, method, group) %>%
tally() -> sub
ggplot(sub, aes(x = group, y = n, fill = method)) +
geom_bar(stat = "identity", position = "dodge") +
facet_wrap(vars(contrast), nrow = 3, ncol = 1, scales = "free_y") +
labs(fill = "Sig. CpGs selected using", y = "No. sig. CpGs mapped to genomic features",
x = "Feature") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))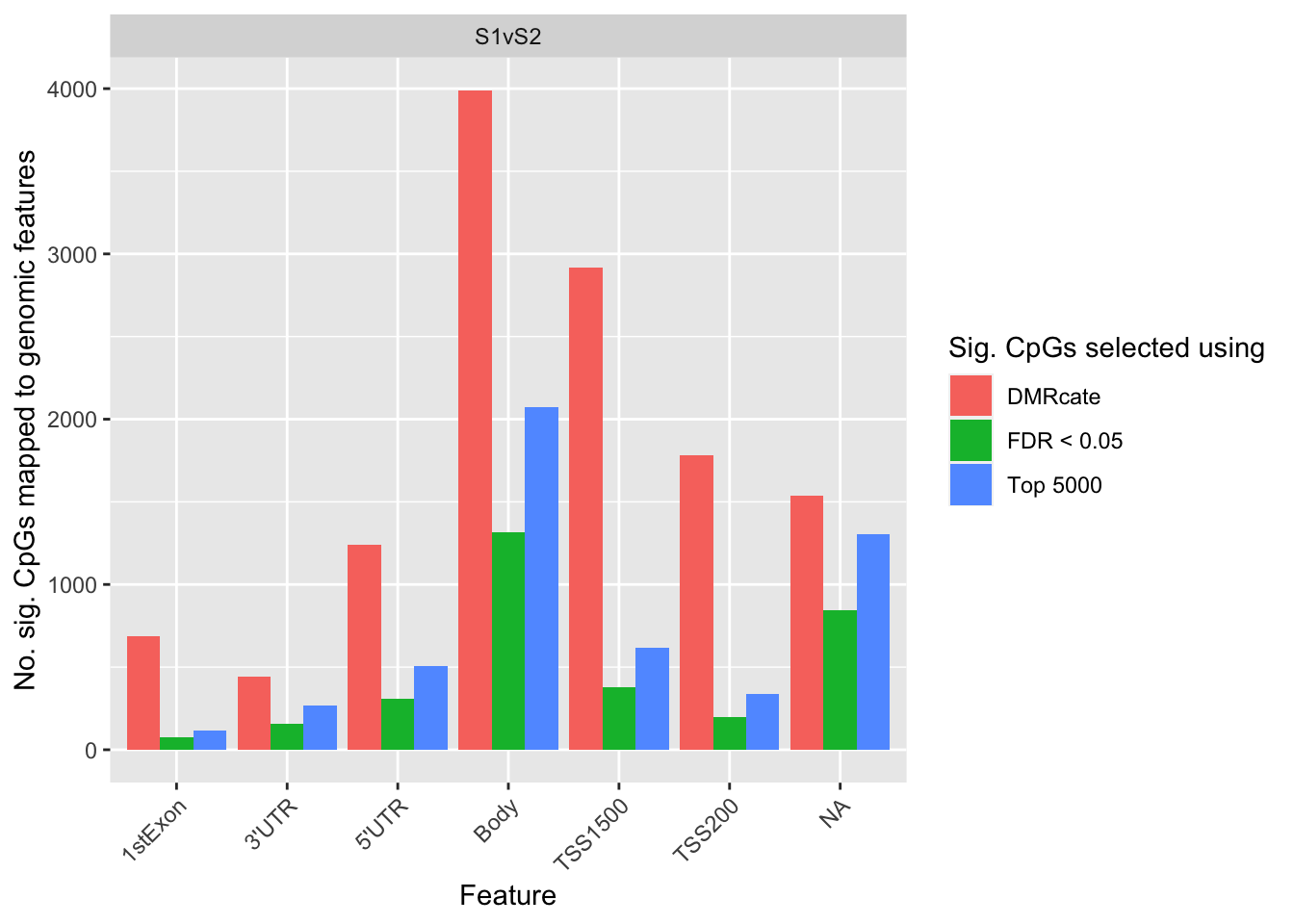
| Version | Author | Date |
|---|---|---|
| 4c57176 | JovMaksimovic | 2021-04-13 |
CpG overlap between region-wise and probe-wise approaches
Compare the CpGs covered by the different approaches.
p <- vector("list", ncol(cont.matrix))
d <- vector("list", length(p))
for(i in 1:length(p)){
cont <- sort(colnames(cont.matrix))[i]
dat %>% dplyr::filter(contrast == cont) %>%
dplyr::select(-contrast) %>%
group_by(cpgs) %>%
summarize(meth = list(method)) %>%
ggplot(aes(x = meth)) +
geom_bar() +
labs(y = "Intersection size", x = "") +
scale_x_upset(sets = c("FDR < 0.05", "DMRcate", "Top 5000")) +
theme(axis.title.y = element_text(size = 10)) -> int
dat %>% dplyr::filter(contrast == cont) %>%
group_by(contrast, method) %>%
tally() %>%
ggplot(aes(x = method, y = n)) +
geom_col(fill="black", position = "dodge") +
geom_text(aes(label = n),
position = position_dodge(0.9),
size = 1.5, hjust = 1.1, vjust = 0.5) +
labs(y = "Set size") +
scale_x_discrete(position = "top",
limits = c("Top 5000", "DMRcate", "FDR < 0.05")) +
scale_y_reverse(labels = scales::format_format(big.mark = " ",
decimal.mark = ".",
scientific = FALSE,
digits = 0),
expand = expansion(mult = c(0.6, 0))) +
coord_flip() +
theme_minimal() +
theme(legend.position = "none",
axis.title.y = element_blank(),
axis.title.x = element_text(size = 8),
axis.text.x = element_blank(),
axis.text.y = element_blank(),
panel.grid = element_blank(),
plot.margin = margin(0, 0, 0, 0,"cm")) -> sets
p[[i]] <- ggarrange(ggarrange(plotlist = list(NULL, sets, NULL),
nrow = 3, heights = c(2.5, 1, 0.1)), int,
ncol = 2,
widths = c(1, 3.5))
d[[i]] <- ggarrange(ggarrange(plotlist = list(NULL, sets, NULL),
nrow = 3, heights = c(4.75, 1, 0.1)), int,
ncol = 2,
widths = c(1, 3.5))
}
d[[1]] 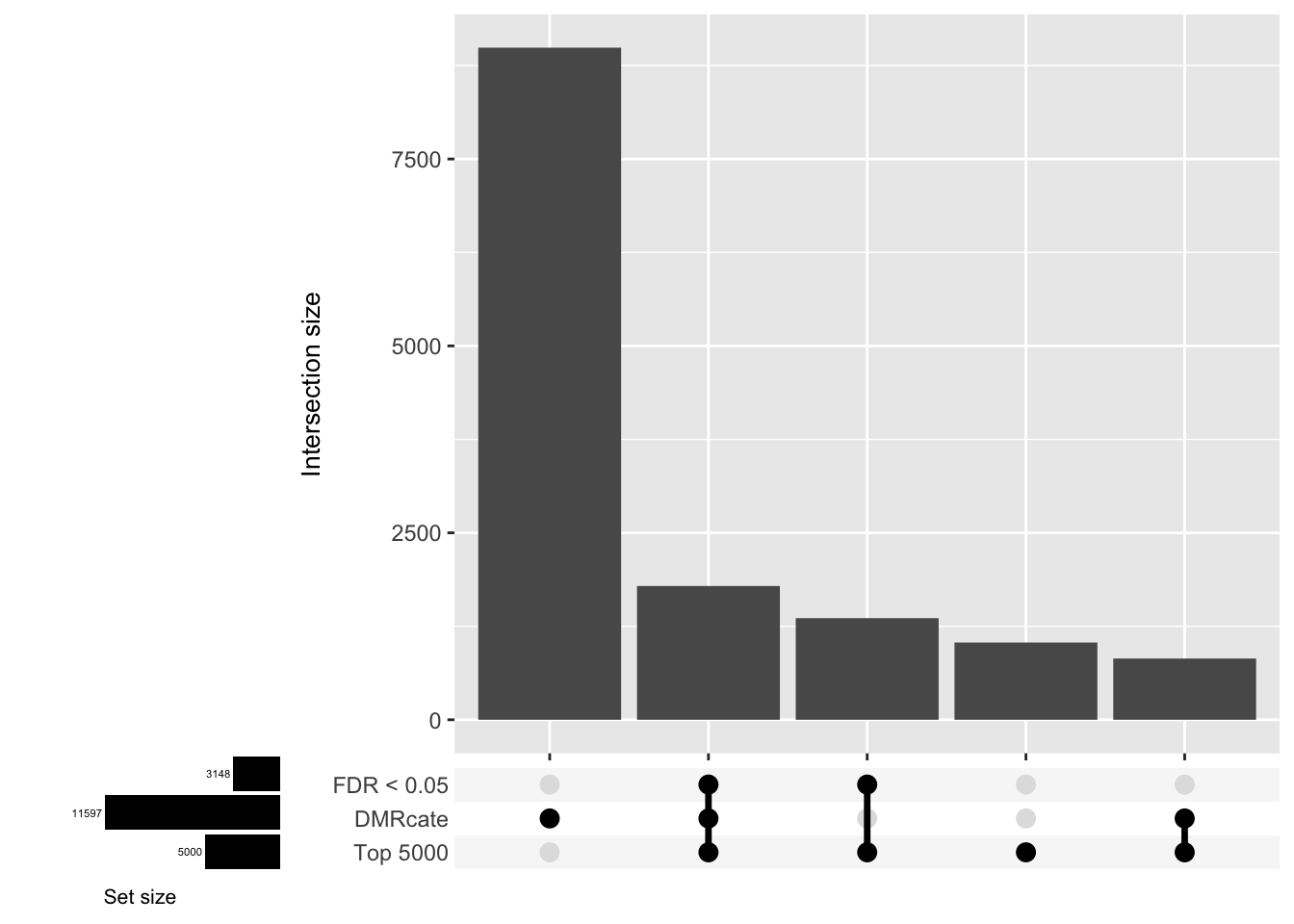
Save figure for use in manuscript.
fig <- here("output/figures/SFig-14D.rds")
saveRDS(p[[1]], fig, compress = FALSE)Gene overlap between region-wise and probe-wise approaches
Compare the genes covered by the different approaches.
p <- vector("list", ncol(cont.matrix))
d <- vector("list", length(p))
for(i in 1:length(p)){
cont <- sort(colnames(cont.matrix))[i]
dat %>% dplyr::filter(contrast == cont) %>%
left_join(flatAnn, by = c("cpgs" = "cpg")) %>%
dplyr::select(method, entrezid) %>%
distinct() %>%
group_by(entrezid) %>%
summarize(meth = list(method)) %>%
ggplot(aes(x = meth)) +
geom_bar() +
labs(y = "Intersection size", x = "") +
scale_x_upset(sets = c("FDR < 0.05", "DMRcate", "Top 5000")) +
theme(axis.title.y = element_text(size = 10)) -> int
dat %>% group_by(contrast, method) %>%
inner_join(flatAnn, by = c("cpgs" = "cpg")) %>%
group_by(contrast, method) %>%
dplyr::select(group_cols(), entrezid) %>%
distinct() %>%
dplyr::filter(contrast == cont) %>%
tally() %>%
ggplot(aes(x = method, y = n)) +
geom_col(fill="black", position = "dodge") +
geom_text(aes(label = n),
position = position_dodge(0.9),
size = 1.5, hjust = 1.1, vjust = 0.5) +
labs(y = "Set size") +
scale_x_discrete(position = "top",
limits = c("Top 5000", "DMRcate", "FDR < 0.05")) +
scale_y_reverse(labels = scales::format_format(big.mark = " ",
decimal.mark = ".",
scientific = FALSE,
digits = 0),
expand = expansion(mult = c(0.6, 0))) +
coord_flip() +
theme_minimal() +
theme(legend.position = "none",
axis.title.y = element_blank(),
axis.title.x = element_text(size = 9),
axis.text.x = element_blank(),
axis.text.y = element_blank(),
panel.grid = element_blank(),
plot.margin = margin(0, 0, 0, 0,"cm")) -> sets
p[[i]] <- ggarrange(ggarrange(plotlist = list(NULL, sets, NULL),
nrow = 3, heights = c(2.5, 1, 0.1)), int,
ncol = 2,
widths = c(1, 3.5))
d[[i]] <- ggarrange(ggarrange(plotlist = list(NULL, sets, NULL),
nrow = 3, heights = c(4.75, 1, 0.1)), int,
ncol = 2,
widths = c(1, 3.5))
}
d[[1]]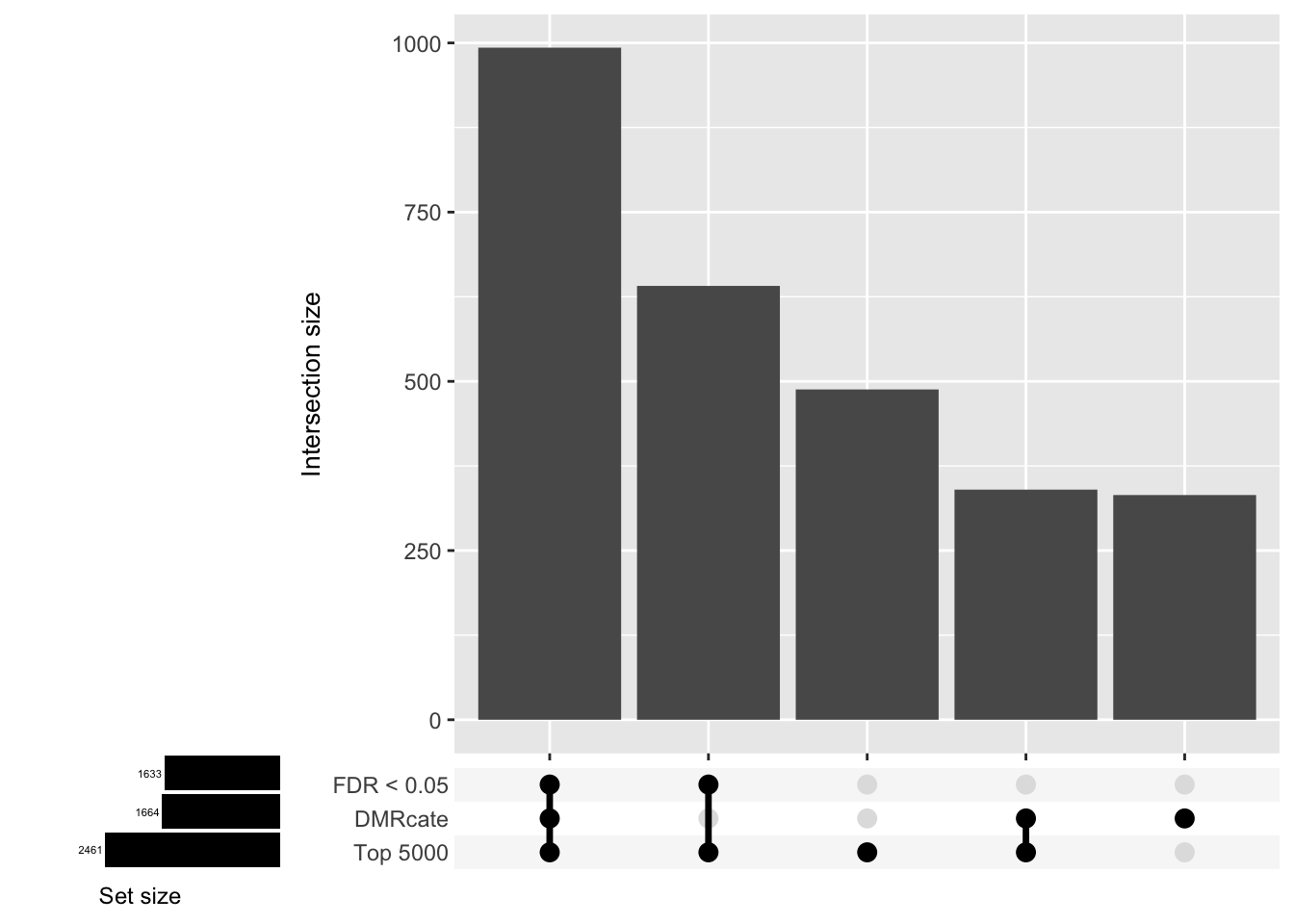
Save figure for use in manuscript.
fig <- here("output/figures/SFig-14F.rds")
saveRDS(p[[1]], fig, compress = FALSE)Effect of DMR cut offs i.e. num probes in region and absolute delta beta
outFile <- here("data/cache-region/dmrcate-GSE45459-params.rds")
dmrParams <- NULL
meanDiffs <- seq(0, 0.2, by = 0.1)
noCpgs <- 2:4
if(!file.exists(outFile)){
for(i in 1:length(dmrList)){
for(j in meanDiffs){
for(k in noCpgs){
keep <- (abs(dmrList[[i]]$meandiff) > j &
dmrList[[i]]$no.cpgs >= k)
tmp <- topGSA(goregion(dmrList[[i]][keep, ], anno = anno,
array.type = "450k"),
number = Inf)
tmp <- rownames_to_column(tmp, var = "GO")[, c("GO", "P.DE")]
tmp$params <- glue("|\u0394\u03B2| = {j}; No. CpGs = {k}")
tmp$contrast <- colnames(cont.matrix)[i]
dmrParams <- bind_rows(dmrParams, tmp)
}
}
}
saveRDS(dmrParams, file = outFile)
} else {
dmrParams <- readRDS(outFile)
}Examine effect of changing DMR parameter cut offs on gene set rankings of GO categories.
p <- vector("list", length(unique(dat$contrast)))
for(i in 1:length(p)){
cont <- sort(unique(dat$contrast))[i]
dmrParams %>% arrange(contrast, params, P.DE) %>%
group_by(contrast, params) %>%
mutate(csum = cumsum(GO %in% immuneGO$GOID)) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 100) %>%
mutate(truth = "ISP Terms") -> immuneSum
dmrParams %>% arrange(contrast, params, P.DE) %>%
group_by(contrast, params) %>%
mutate(csum = cumsum(GO %in% topGOSets$ID[topGOSets$contrast %in%
cont])) %>%
mutate(rank = 1:n()) %>%
dplyr::filter(rank <= 100) %>%
mutate(truth = "Array Terms") -> rnaseqSum
truthSum <- bind_rows(immuneSum, rnaseqSum)
p[[i]] <- ggplot(truthSum, aes(x = rank, y = csum, colour = params)) +
geom_line() +
facet_wrap(vars(truth)) +
geom_vline(xintercept = 10, linetype = "dotted") +
labs(colour = "Parameters", x = "Rank",
y = glue("Cumulative no. truth sets")) +
theme(legend.position = "right") +
ggtitle(cont)
}
p[[1]]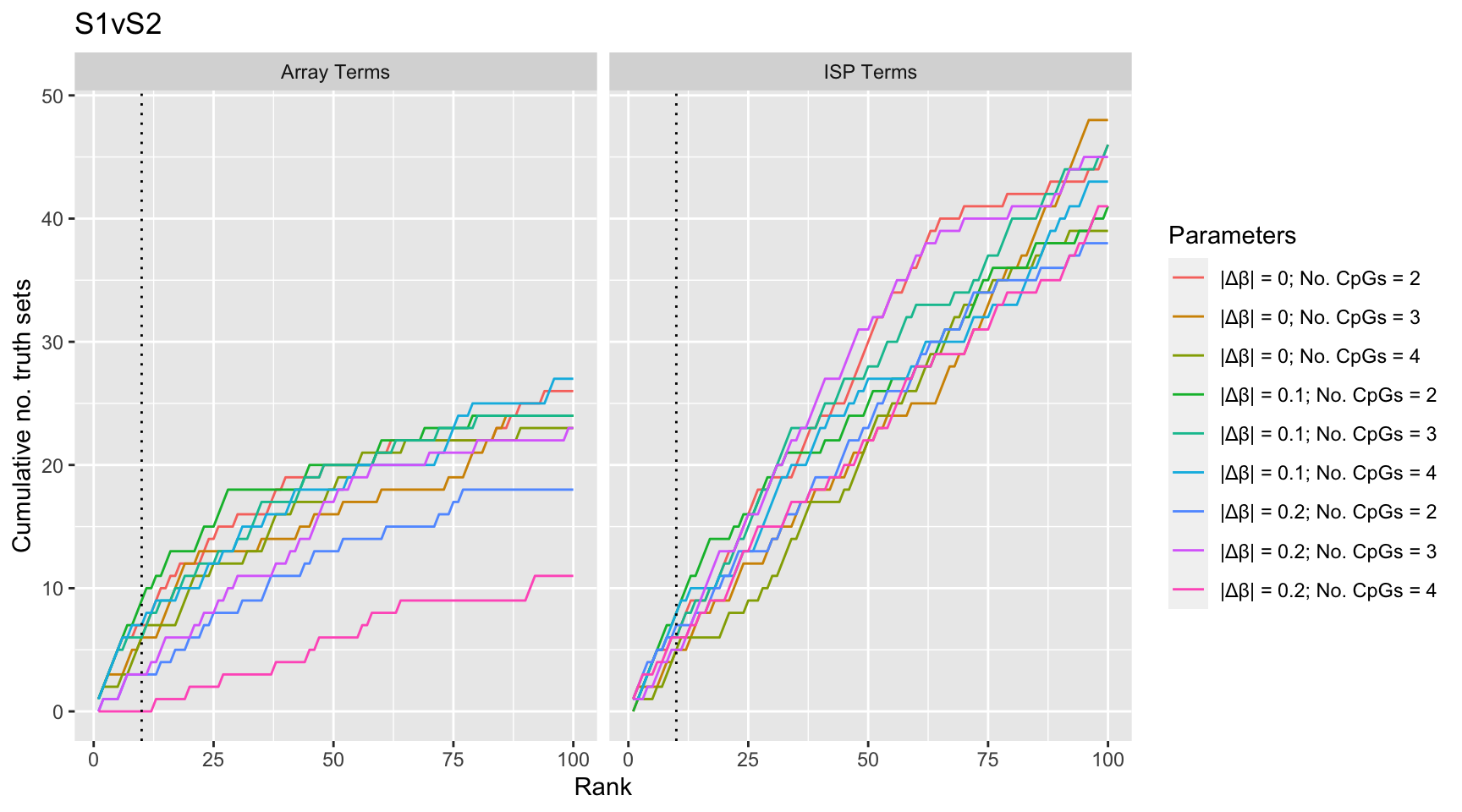
Save figure for use in manuscript.
fig <- here("output/figures/SFig-15C.rds")
saveRDS(p[[1]], fig, compress = FALSE)
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Mojave 10.14.6
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_AU.UTF-8/en_AU.UTF-8/en_AU.UTF-8/C/en_AU.UTF-8/en_AU.UTF-8
attached base packages:
[1] grid stats4 parallel stats graphics grDevices utils
[8] datasets methods base
other attached packages:
[1] TxDb.Hsapiens.UCSC.hg19.knownGene_3.2.2
[2] GenomicFeatures_1.42.3
[3] AnnotationDbi_1.52.0
[4] ggpubr_0.4.0
[5] ggupset_0.3.0
[6] tibble_3.1.0
[7] patchwork_1.1.1
[8] dplyr_1.0.5
[9] UpSetR_1.4.0
[10] glue_1.4.2
[11] ggplot2_3.3.3
[12] missMethyl_1.24.0
[13] IlluminaHumanMethylationEPICanno.ilm10b4.hg19_0.6.0
[14] IlluminaHumanMethylation450kanno.ilmn12.hg19_0.6.0
[15] reshape2_1.4.4
[16] BiocParallel_1.24.1
[17] limma_3.46.0
[18] paletteer_1.3.0
[19] ChAMP_2.20.1
[20] RPMM_1.25
[21] cluster_2.1.1
[22] DT_0.17
[23] IlluminaHumanMethylationEPICmanifest_0.3.0
[24] Illumina450ProbeVariants.db_1.26.0
[25] DMRcate_2.4.1
[26] ChAMPdata_2.22.0
[27] minfi_1.36.0
[28] bumphunter_1.32.0
[29] locfit_1.5-9.4
[30] iterators_1.0.13
[31] foreach_1.5.1
[32] Biostrings_2.58.0
[33] XVector_0.30.0
[34] SummarizedExperiment_1.20.0
[35] Biobase_2.50.0
[36] MatrixGenerics_1.2.1
[37] matrixStats_0.58.0
[38] GenomicRanges_1.42.0
[39] GenomeInfoDb_1.26.7
[40] IRanges_2.24.1
[41] S4Vectors_0.28.1
[42] BiocGenerics_0.36.0
[43] here_1.0.1
[44] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Hmisc_4.5-0
[2] Rsamtools_2.6.0
[3] rprojroot_2.0.2
[4] crayon_1.4.1
[5] MASS_7.3-53.1
[6] rhdf5filters_1.2.0
[7] nlme_3.1-152
[8] backports_1.2.1
[9] sva_3.38.0
[10] impute_1.64.0
[11] rlang_0.4.10
[12] readxl_1.3.1
[13] DSS_2.38.0
[14] globaltest_5.44.0
[15] bit64_4.0.5
[16] isva_1.9
[17] rngtools_1.5
[18] methylumi_2.36.0
[19] haven_2.3.1
[20] tidyselect_1.1.0
[21] rio_0.5.26
[22] XML_3.99-0.6
[23] nleqslv_3.3.2
[24] tidyr_1.1.3
[25] GenomicAlignments_1.26.0
[26] xtable_1.8-4
[27] magrittr_2.0.1
[28] evaluate_0.14
[29] zlibbioc_1.36.0
[30] rstudioapi_0.13
[31] doRNG_1.8.2
[32] whisker_0.4
[33] bslib_0.2.4
[34] rpart_4.1-15
[35] ensembldb_2.14.0
[36] shiny_1.6.0
[37] xfun_0.22
[38] askpass_1.1
[39] clue_0.3-58
[40] multtest_2.46.0
[41] interactiveDisplayBase_1.28.0
[42] base64_2.0
[43] biovizBase_1.38.0
[44] scrime_1.3.5
[45] dendextend_1.14.0
[46] png_0.1-7
[47] permute_0.9-5
[48] reshape_0.8.8
[49] withr_2.4.1
[50] lumi_2.42.0
[51] bitops_1.0-6
[52] plyr_1.8.6
[53] cellranger_1.1.0
[54] AnnotationFilter_1.14.0
[55] JADE_2.0-3
[56] pillar_1.5.1
[57] cachem_1.0.4
[58] fs_1.5.0
[59] DelayedMatrixStats_1.12.3
[60] vctrs_0.3.7
[61] ellipsis_0.3.1
[62] generics_0.1.0
[63] tools_4.0.3
[64] foreign_0.8-81
[65] munsell_0.5.0
[66] DelayedArray_0.16.3
[67] fastmap_1.1.0
[68] compiler_4.0.3
[69] abind_1.4-5
[70] httpuv_1.5.5
[71] rtracklayer_1.50.0
[72] geneLenDataBase_1.26.0
[73] ExperimentHub_1.16.0
[74] lemon_0.4.5
[75] beanplot_1.2
[76] Gviz_1.34.1
[77] plotly_4.9.3
[78] GenomeInfoDbData_1.2.4
[79] gridExtra_2.3
[80] DNAcopy_1.64.0
[81] edgeR_3.32.1
[82] lattice_0.20-41
[83] utf8_1.2.1
[84] later_1.1.0.1
[85] BiocFileCache_1.14.0
[86] jsonlite_1.7.2
[87] affy_1.68.0
[88] scales_1.1.1
[89] carData_3.0-4
[90] sparseMatrixStats_1.2.1
[91] genefilter_1.72.1
[92] lazyeval_0.2.2
[93] promises_1.2.0.1
[94] car_3.0-10
[95] doParallel_1.0.16
[96] latticeExtra_0.6-29
[97] R.utils_2.10.1
[98] goseq_1.42.0
[99] checkmate_2.0.0
[100] rmarkdown_2.7
[101] openxlsx_4.2.3
[102] nor1mix_1.3-0
[103] cowplot_1.1.1
[104] statmod_1.4.35
[105] siggenes_1.64.0
[106] forcats_0.5.1
[107] dichromat_2.0-0
[108] BSgenome_1.58.0
[109] HDF5Array_1.18.1
[110] bsseq_1.26.0
[111] survival_3.2-10
[112] yaml_2.2.1
[113] htmltools_0.5.1.1
[114] memoise_2.0.0
[115] VariantAnnotation_1.36.0
[116] quadprog_1.5-8
[117] viridisLite_0.3.0
[118] digest_0.6.27
[119] assertthat_0.2.1
[120] mime_0.10
[121] rappdirs_0.3.3
[122] BiasedUrn_1.07
[123] RSQLite_2.2.5
[124] data.table_1.14.0
[125] blob_1.2.1
[126] R.oo_1.24.0
[127] preprocessCore_1.52.1
[128] fastICA_1.2-2
[129] shinythemes_1.2.0
[130] splines_4.0.3
[131] Formula_1.2-4
[132] labeling_0.4.2
[133] rematch2_2.1.2
[134] Rhdf5lib_1.12.1
[135] illuminaio_0.32.0
[136] AnnotationHub_2.22.0
[137] ProtGenerics_1.22.0
[138] RCurl_1.98-1.3
[139] broom_0.7.6
[140] hms_1.0.0
[141] rhdf5_2.34.0
[142] colorspace_2.0-0
[143] base64enc_0.1-3
[144] BiocManager_1.30.12
[145] nnet_7.3-15
[146] sass_0.3.1
[147] GEOquery_2.58.0
[148] Rcpp_1.0.6
[149] mclust_5.4.7
[150] fansi_0.4.2
[151] R6_2.5.0
[152] lifecycle_1.0.0
[153] zip_2.1.1
[154] curl_4.3
[155] kpmt_0.1.0
[156] ggsignif_0.6.1
[157] affyio_1.60.0
[158] jquerylib_0.1.3
[159] Matrix_1.3-2
[160] qvalue_2.22.0
[161] ROC_1.66.0
[162] org.Hs.eg.db_3.12.0
[163] RColorBrewer_1.1-2
[164] stringr_1.4.0
[165] IlluminaHumanMethylation450kmanifest_0.4.0
[166] htmlwidgets_1.5.3
[167] biomaRt_2.46.3
[168] purrr_0.3.4
[169] marray_1.68.0
[170] mgcv_1.8-34
[171] openssl_1.4.3
[172] htmlTable_2.1.0
[173] codetools_0.2-18
[174] GO.db_3.12.1
[175] gtools_3.8.2
[176] prettyunits_1.1.1
[177] dbplyr_2.1.1
[178] R.methodsS3_1.8.1
[179] gtable_0.3.0
[180] DBI_1.1.1
[181] git2r_0.28.0
[182] wateRmelon_1.34.0
[183] httr_1.4.2
[184] highr_0.8
[185] KernSmooth_2.23-18
[186] stringi_1.5.3
[187] progress_1.2.2
[188] farver_2.1.0
[189] annotate_1.68.0
[190] viridis_0.5.1
[191] xml2_1.3.2
[192] combinat_0.0-8
[193] readr_1.4.0
[194] BiocVersion_3.12.0
[195] bit_4.0.4
[196] jpeg_0.1-8.1
[197] pkgconfig_2.0.3
[198] rstatix_0.7.0
[199] knitr_1.31