Figure 3
Jovana Maksimovic
April 01, 2026
Last updated: 2026-04-01
Checks: 7 0
Knit directory:
paediatric-cf-inflammation-citeseq/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20240216) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 5879432. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: analysis/obsolete/
Ignored: code/obsolete/
Ignored: data/.DS_Store
Ignored: data/C133_Neeland_batch0/
Ignored: data/C133_Neeland_batch1/
Ignored: data/C133_Neeland_batch2/
Ignored: data/C133_Neeland_batch3/
Ignored: data/C133_Neeland_batch4/
Ignored: data/C133_Neeland_batch5/
Ignored: data/C133_Neeland_batch6/
Ignored: data/C133_Neeland_merged/
Ignored: data/Neeland_processed_data_1.h5ad
Ignored: data/Neeland_processed_data_2.h5ad
Ignored: data/Neeland_processed_data_3.h5ad
Ignored: data/intermediate_objects/.DS_Store
Ignored: data/updated_h5ad_files/
Ignored: output/.DS_Store
Ignored: renv/library/
Ignored: renv/staging/
Untracked files:
Untracked: C133_Neeland_preprocessed_SCEs.tar.gz
Untracked: analysis/cellxgene_submission.Rmd
Untracked: data/GOBP_CYTOKINE_MEDIATED_SIGNALING_PATHWAY.v2025.1.Hs.tsv
Untracked: data/cellxgene_cell_ontologies_ann_level_3.xlsx
Untracked: data/gencode.v44.primary_assembly.annotation.gtf
Unstaged changes:
Modified: .DS_Store
Modified: analysis/13.0_DGE_analysis_macrophages.Rmd
Modified: analysis/13.1_DGE_analysis_macro-alveolar.Rmd
Modified: analysis/13.2_DGE_analysis_macro-APOC2+.Rmd
Modified: analysis/13.3_DGE_analysis_macro-CCL.Rmd
Modified: analysis/13.4_DGE_analysis_macro-IFI27.Rmd
Modified: analysis/13.5_DGE_analysis_macro-lipid.Rmd
Modified: analysis/13.6_DGE_analysis_macro-monocyte-derived.Rmd
Modified: analysis/13.7_DGE_analysis_macro-proliferating.Rmd
Modified: analysis/14.0_DGE_analysis_CD4-T-cells.Rmd
Modified: analysis/14.1_DGE_analysis_CD8-T-cells.Rmd
Modified: analysis/14.2_DGE_analysis_DC-cells.Rmd
Modified: analysis/15.0_proportions_analysis_ann_level_1.Rmd
Modified: analysis/15.1_proportions_analysis_ann_level_3_non-macrophages.Rmd
Modified: analysis/15.2_proportions_analysis_ann_level_3_macrophages.Rmd
Modified: output/dge_analysis/macrophages/CAM.FIBROSIS.CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.FIBROSIS.CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.FIBROSIS.CF.LUMA_IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.FIBROSIS.CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/CAM.FIBROSIS.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.GO.CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.GO.CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.GO.CF.LUMA_IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.GO.CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/CAM.GO.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.HALLMARK.CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.HALLMARK.CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.HALLMARK.CF.LUMA_IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.HALLMARK.CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/CAM.HALLMARK.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.REACTOME.CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.REACTOME.CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.REACTOME.CF.LUMA_IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.REACTOME.CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/CAM.REACTOME.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.WP.CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.WP.CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CAM.WP.CF.LUMA_IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CAM.WP.CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/CAM.WP.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/CF.LUMA_IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/ORA.GO.CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/ORA.GO.CF.NO_MOD.SvCF.NO_MOD.M.csv
Modified: output/dge_analysis/macrophages/ORA.GO.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macrophages/ORA.HALLMARK.CF.IVAvCF.NO_MOD.csv
Modified: output/dge_analysis/macrophages/ORA.REACTOME.CF.NO_MODvNON_CF.CTRL.csv
Modified: output/pdf_figures/Figure_1.pdf
Modified: output/pdf_figures/Figure_2.pdf
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/16.2_Figure_3.Rmd) and
HTML (docs/16.2_Figure_3.html) files. If you’ve configured
a remote Git repository (see ?wflow_git_remote), click on
the hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 5879432 | Jovana Maksimovic | 2026-04-01 | wflow_publish(c("analysis/16.0_Figure_1.Rmd", "analysis/16.1_Figure_2.Rmd", |
| html | 4b21e90 | Jovana Maksimovic | 2026-03-23 | Build site. |
| Rmd | 31e1e1a | Jovana Maksimovic | 2026-03-23 | wflow_publish("analysis/16.2_Figure_3.Rmd") |
| html | 91b42ff | Jovana Maksimovic | 2026-03-23 | Build site. |
| Rmd | 382297f | Jovana Maksimovic | 2026-03-23 | wflow_publish("analysis/16.2_Figure_3.Rmd") |
| html | aa4438b | Jovana Maksimovic | 2025-09-10 | Build site. |
| Rmd | ac4f646 | Jovana Maksimovic | 2025-09-10 | wflow_publish("analysis/16.2_Figure_3.Rmd") |
| html | 46fd27d | Jovana Maksimovic | 2025-03-03 | Build site. |
| Rmd | 69271fe | Jovana Maksimovic | 2025-03-03 | wflow_publish("analysis/16.2_Figure_3.Rmd") |
Load libraries.
suppressPackageStartupMessages({
library(SingleCellExperiment)
library(edgeR)
library(tidyverse)
library(ggplot2)
library(Seurat)
library(glmGamPoi)
library(dittoSeq)
library(here)
library(clustree)
library(patchwork)
library(AnnotationDbi)
library(org.Hs.eg.db)
library(glue)
library(speckle)
library(tidyHeatmap)
library(paletteer)
library(dsb)
library(ggh4x)
library(readxl)
library(purrr)
})
source(here("code/utility.R"))Load data
files <- list.files(here("data/C133_Neeland_merged"),
pattern = "C133_Neeland_full_clean.*(macrophages|t_cells|other_cells)_annotated_diet.SEU.rds",
full.names = TRUE)
seuLst <- lapply(files[2:4], function(f) readRDS(f))
seu <- merge(seuLst[[1]],
y = c(seuLst[[2]],
seuLst[[3]]))
seuAn object of class Seurat
21568 features across 194407 samples within 1 assay
Active assay: RNA (21568 features, 0 variable features) used (Mb) gc trigger (Mb) limit (Mb) max used (Mb)
Ncells 10386807 554.8 18230718 973.7 NA 13230050 706.6
Vcells 1351268542 10309.4 3689744520 28150.6 65536 3548606227 27073.8Create sample meta data table.
props <- getTransformedProps(clusters = seu$ann_level_3,
sample = seu$sample.id, transform="asin")
seu@meta.data %>%
dplyr::select(sample.id,
Participant,
Disease,
Treatment,
Severity,
Group,
Group_severity,
Batch,
Age,
Sex) %>%
left_join(props$Counts %>%
data.frame %>%
group_by(sample) %>%
summarise(ncells = sum(Freq)),
by = c("sample.id" = "sample")) %>%
distinct() -> info
head(info) %>% knitr::kable()| sample.id | Participant | Disease | Treatment | Severity | Group | Group_severity | Batch | Age | Sex | ncells |
|---|---|---|---|---|---|---|---|---|---|---|
| sample_33.1 | sample_33 | CF | treated (ivacaftor) | severe | CF.IVA | CF.IVA.S | 1 | 5.950685 | M | 2139 |
| sample_25.1 | sample_25 | CF | untreated | severe | CF.NO_MOD | CF.NO_MOD.S | 1 | 4.910000 | F | 3272 |
| sample_29.1 | sample_29 | CF | untreated | severe | CF.NO_MOD | CF.NO_MOD.S | 1 | 5.989041 | F | 1568 |
| sample_27.1 | sample_27 | CF | treated (ivacaftor) | mild | CF.IVA | CF.IVA.M | 1 | 4.917808 | M | 2467 |
| sample_32.1 | sample_32 | CF | untreated | mild | CF.NO_MOD | CF.NO_MOD.M | 1 | 5.926027 | F | 2963 |
| sample_26.1 | sample_26 | CF | untreated | mild | CF.NO_MOD | CF.NO_MOD.M | 1 | 5.049315 | M | 2040 |
Prepare figure panels
Set up short/better names for cell types and conditions in figure.
lab_map <- c(
"macro-alveolar" = "AM",
"macro-IGF1" = "AM.IGF1",
"macro-CCL" = "AM.CCL",
"macro-lipid" = "AM.Lipid",
"macro-MT" = "AM.MT",
"macro-IFN" = "AM.IFN",
"macro-APOC2+" = "AM.APOC2",
"macro-CCL18" = "AM.CCL18",
"macro-IFI27" = "AM.IFI27",
"macro-monocyte-derived" = "Mac.Mono.Deriv",
"macro-interstitial" = "Mac.Interstitial",
"macro-lipid-APOC2+" = "AM.Lipid.APOC2",
"macro-T" = "Mac.T",
"macro-IFI27+CCL18+" = "AM.IFI27.CCL18",
"macro-IFI27+APOC2+" = "AM.IFI27.APOC2",
"macro-proliferating" = "Mac.Prolif",
"macrophages" = "All Macs (exc. Prolif)",
"CD4 T-reg" = "CD4 T-reg",
"monocytes" = "monocytes",
"NK-T cells" = "NK-T cells"
)
samp_map <-
c(
"CF.IVA" = "CF (iva)",
"CF.LUMA_IVA" = "CF (luma/iva)",
"CF.NO_MOD" = "CF (no mod)",
"NON_CF.CTRL" = "Non-CF control",
"healthy" = "Control",
"mild" = "Mild",
"severe" = "Severe"
)# 3A: monocytes, NK-T cells, CD4 Tregs, macro-IGF1
props <- getTransformedProps(clusters = seu$ann_level_3[!str_detect(seu$ann_level_3, "macro")],
sample = seu$sample.id[!str_detect(seu$ann_level_3, "macro")], transform="asin")
props$Proportions %>% data.frame %>%
left_join(info,
by = c("sample" = "sample.id")) %>%
dplyr::filter(Group %in% c("CF.NO_MOD", "NON_CF.CTRL"),
clusters %in% c("monocytes",
"NK-T cells",
"CD4 T-reg")) -> dat
sig_names <- as_labeller(lab_map)
prop.non_macros.fit <- readRDS(here("data/intermediate_objects/prop.ann_level3.non-macrophages.fit.rds"))
prop.macros.fit <- readRDS(here("data/intermediate_objects/prop.ann_level3.macrophages.fit.rds"))
fits <- list(
non_macros = prop.non_macros.fit,
macros = prop.macros.fit
)
stats_all <- map_dfr(
fits,
~ topTable(.x,
coef = "CF.NO_MODvNON_CF.CTRL",
n = Inf) %>%
rownames_to_column("clusters"),
.id = "fit"
)
stat_labels <- stats_all %>%
filter(clusters %in% unique(dat$clusters)) %>%
distinct(clusters, .keep_all = TRUE) %>%
mutate(
sig = case_when(
adj.P.Val < 0.001 ~ "***",
adj.P.Val < 0.01 ~ "**",
adj.P.Val < 0.05 ~ "*",
TRUE ~ ""
),
label = sprintf("p = %.2g\nFDR = %.2g%s",
P.Value, adj.P.Val, sig)
)
y_pos <- dat %>%
group_by(clusters) %>%
summarise(y = max(Freq, na.rm = TRUE) * 0.9)
stat_labels <- left_join(stat_labels, y_pos, by = "clusters")
pal <- setNames(RColorBrewer::brewer.pal(7, "Set2"),
unname(samp_map))
dat %>%
mutate(Group = samp_map[Group]) %>%
ggplot(aes(x = Group,
y = Freq,
colour = Group)) +
geom_jitter(stat = "identity",
width = 0.15,
size = 1) +
theme_classic() +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.x = element_blank(),
axis.text.y = element_text(size = 7),
legend.position = "bottom",
legend.direction = "horizontal",
strip.text = element_text(size = 8)) +
labs(x = "Group", y = "Proportion") +
facet_wrap(~clusters, scales = "free_y", ncol = 4,
labeller = sig_names) +
stat_summary(
geom = "point",
fun.y = "mean",
col = "black",
shape = "_",
size = 10) +
scale_color_manual(values = pal) +
geom_text(
data = stat_labels,
aes(x = 1.5, y = y, label = label),
inherit.aes = FALSE,
size = 3) -> p1
p1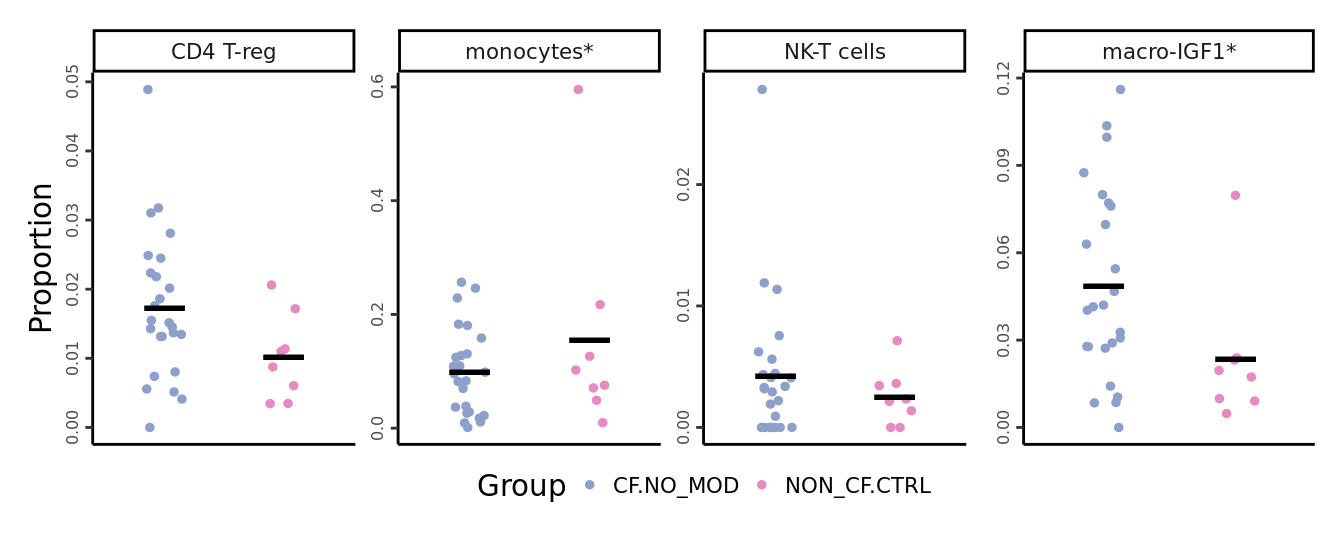
props <- getTransformedProps(clusters = seu$ann_level_3[str_detect(seu$ann_level_3, "macro")],
sample = seu$sample.id[str_detect(seu$ann_level_3, "macro")], transform="asin")
props$Proportions %>% data.frame %>%
left_join(info,
by = c("sample" = "sample.id")) %>%
dplyr::filter(Group %in% c("CF.NO_MOD", "NON_CF.CTRL"),
clusters %in% c("macro-IGF1")) -> dat
stat_labels <- stats_all %>%
filter(clusters %in% unique(dat$clusters)) %>%
distinct(clusters, .keep_all = TRUE) %>%
mutate(
sig = case_when(
adj.P.Val < 0.001 ~ "***",
adj.P.Val < 0.01 ~ "**",
adj.P.Val < 0.05 ~ "*",
TRUE ~ ""
),
label = sprintf("p = %.2g\nFDR = %.2g%s",
P.Value, adj.P.Val, sig)
)
y_pos <- dat %>%
group_by(clusters) %>%
summarise(y = max(Freq, na.rm = TRUE) * 0.9)
stat_labels <- left_join(stat_labels, y_pos, by = "clusters")
dat %>%
mutate(Group = samp_map[Group]) %>%
ggplot(aes(x = Group,
y = Freq,
colour = Group)) +
geom_jitter(stat = "identity",
width = 0.15,
size = 1) +
theme_classic() +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.x = element_blank(),
axis.text.y = element_text(size = 7),
legend.position = "bottom",
legend.direction = "horizontal",
strip.text = element_text(size = 8)) +
labs(x = "Group", y = "Proportion") +
facet_wrap(~clusters, scales = "free_y", ncol = 4,
labeller = sig_names) +
stat_summary(
geom = "point",
fun.y = "mean",
col = "black",
shape = "_",
size = 10) +
scale_color_manual(values = pal) +
geom_text(
data = stat_labels,
aes(x = 1.5, y = y, label = label),
inherit.aes = FALSE,
size = 3) -> p2
layout <- "AAAB"
cf_props <- (p1 +
(p2 + theme(axis.title.y = element_blank()))) +
plot_layout(design = layout, guides = "collect") &
theme(axis.text.y = element_text(size = 6,
angle = 90,
hjust = 0.5),
legend.text = element_text(size = 8),
legend.key.spacing = unit(0, "lines"),
legend.margin = margin(-0.5,0,0,0, unit="lines"),
legend.direction = "horizontal",
legend.position = "bottom")
cf_props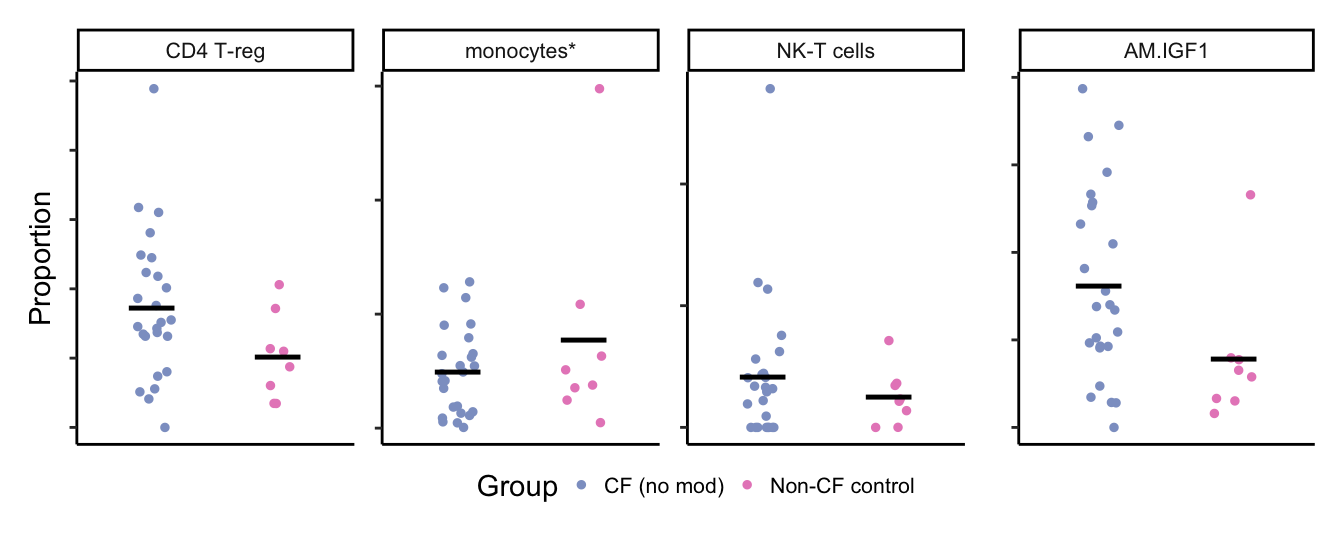
seu@meta.data %>%
data.frame %>%
dplyr::select(ann_level_2) %>%
dplyr::filter(str_detect(ann_level_2, "macro")) %>%
group_by(ann_level_2) %>%
count() %>%
janitor::adorn_totals(name = "macrophages") %>%
arrange(-n) %>%
dplyr::rename(cell = ann_level_2) -> cell_freq
cell_freq cell n
macrophages 165209
macro-alveolar 52563
macro-IFI27 24864
macro-CCL 21246
macro-monocyte-derived 13461
macro-APOC2+ 13354
macro-lipid 12452
macro-IGF1 8229
macro-proliferating 6821
macro-MT 4037
macro-interstitial 3412
macro-T 2722
macro-IFN 2048files <- list.files(here("data/intermediate_objects"),
pattern = "macro.*all_samples",
full.names = TRUE)
cutoff <- 0.05
cont_name <- "CF.NO_MODvNON_CF.CTRL"
lfc_cutoff <- log2(1.1)
suffix <- ".all_samples.fit.rds"
get_deg_data(files, cont_name, cell_freq, treat_lfc = lfc_cutoff,
suffix = suffix) -> datdat %>%
dplyr::select(gene, cell, logFC) %>%
distinct() %>%
pivot_wider(
names_from = cell, # Column whose values become new column names
values_from = logFC,
values_fill = list(logFC = NA)) %>%
arrange(across(all_of(cell_freq$cell[cell_freq$cell %in% dat$cell]))) %>%
column_to_rownames(var = "gene") -> dat_lfccol_fun <- circlize::colorRamp2(seq(0, 100000, length.out = 9),
(RColorBrewer::brewer.pal(9, "PiYG")))
col_split <- c(rep("aggregate", 1), rep("sub-type", ncol(dat_lfc) - 1))
pal_dt <- c(paletteer::paletteer_d("RColorBrewer::Set1")[2:1], "grey")
col_lfc_fun <- circlize::colorRamp2(seq(-2, 2, length.out = 3),
c(pal_dt[1], "white", pal_dt[2]))
ComplexHeatmap::HeatmapAnnotation(df = cell_freq %>%
dplyr::filter(cell %in% colnames(dat_lfc)) %>%
column_to_rownames(var = "cell") %>%
dplyr::rename(`No. cells` = n),
which = "column",
show_annotation_name = FALSE,
col = list(`No. cells` = col_fun),
annotation_legend_param = list(
`No. cells` = list(direction = "vertical"))) -> col_ann
ComplexHeatmap::HeatmapAnnotation(df = data.frame(`Sig. ≥2 cell types` = (rowSums(!is.na(dat_lfc)) > 1),
check.names = FALSE),
which = "row",
col = list(`Sig. ≥2 cell types` = c("FALSE" = "#fdcce5","TRUE" = "#8bd3c7")),
annotation_legend_param = list(
`Sig. ≥2 cell types` = list(direction = "vertical",
ncol = 1)),
show_annotation_name = FALSE) -> row_ann
colnames(dat_lfc) <- lab_map[colnames(dat_lfc)]
ComplexHeatmap::Heatmap(dat_lfc,
name = "logFC",
column_split = col_split,
column_title = NULL,
cluster_rows = FALSE,
cluster_columns = FALSE,
rect_gp = grid::gpar(col = "white", lwd = 1),
row_names_gp = grid::gpar(fontsize = 7),
column_names_gp = grid::gpar(fontsize = 7),
col = col_lfc_fun,
top_annotation = col_ann,
right_annotation = row_ann,
heatmap_legend_param = list(direction = "vertical")) -> plot_lfc
ComplexHeatmap::draw(as(list(plot_lfc), "HeatmapList"),
heatmap_legend_side = "right",
annotation_legend_side = "right",
merge_legends = TRUE) -> plot_lfc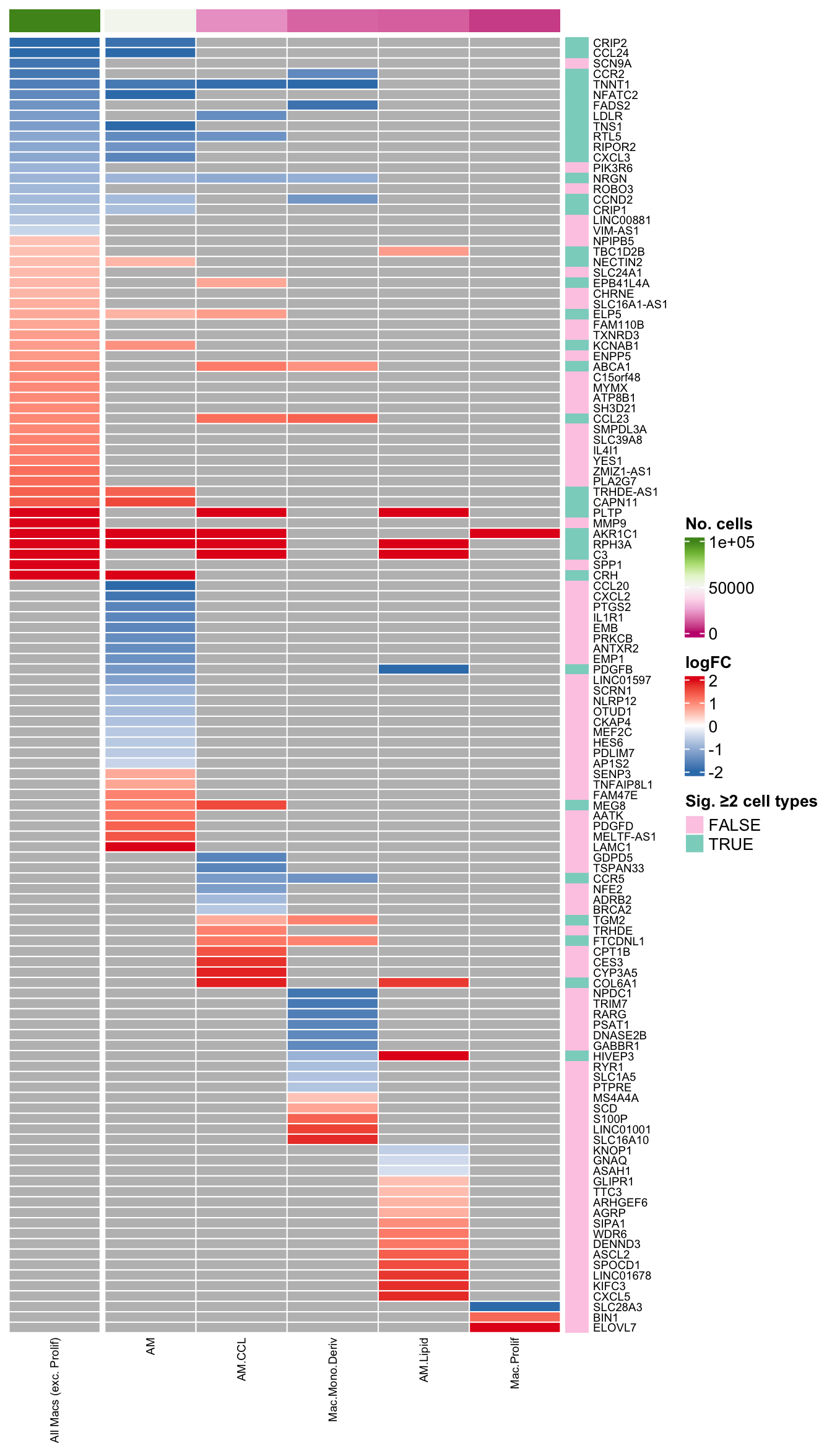
| Version | Author | Date |
|---|---|---|
| aa4438b | Jovana Maksimovic | 2025-09-10 |
plot_lfc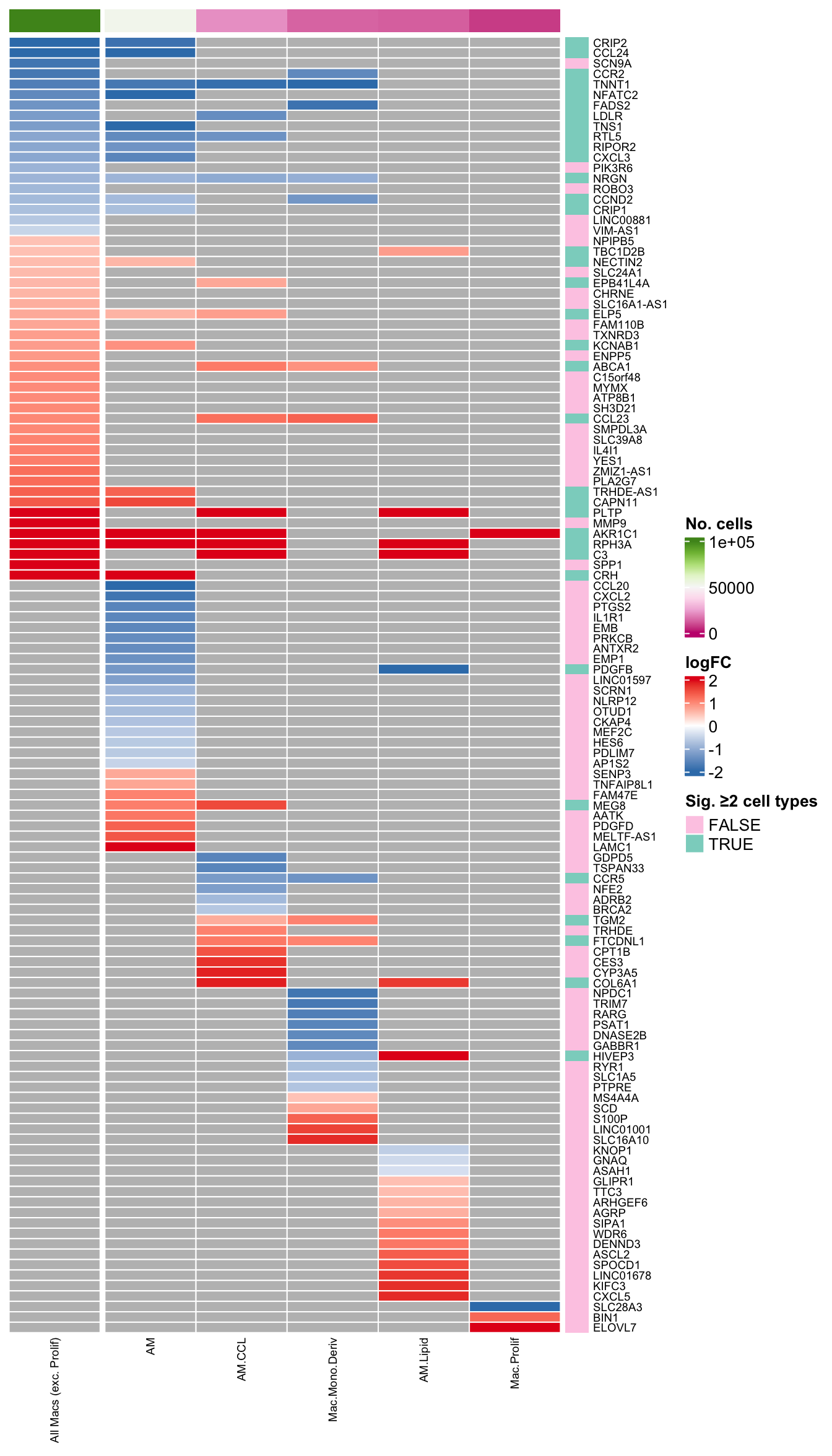
| Version | Author | Date |
|---|---|---|
| aa4438b | Jovana Maksimovic | 2025-09-10 |
bind_rows(lapply(files, function(f){
deg_results <- readRDS(f)
lrt <- glmLRT(deg_results$fit,
contrast = deg_results$contr[,cont_name])
tmp <- cbind(summary(decideTests(lrt, p.value = cutoff)) %>% data.frame,
cell = str_extract(basename(f), "^[^.]+"))
tmp
})) -> dat_degdat_deg %>%
left_join(cell_freq) -> dat_deg
pal_dt <- c(paletteer::paletteer_d("RColorBrewer::Set1")[2:1], "grey")
dat_deg %>%
dplyr::filter(Var1 != "NotSig") %>%
mutate(cell = lab_map[as.character(cell)]) %>%
ggplot(aes(x = fct_reorder(cell, n), y = Freq, fill = Var1)) +
geom_col(position = "dodge") +
scale_fill_manual(values = pal_dt) +
theme_classic() +
theme(axis.text.y = element_text(angle = -45,
hjust = 1,
vjust = 1,
size = 7),
legend.position = "top") +
geom_text(aes(label = Freq),
position = position_dodge(width = 0.9),
vjust = -0.5,
angle = 270,
size = 2.5) +
labs(x = "Cell Type",
y = "No. DEG (FDR < 0.05)",
fill = "Direction") +
coord_flip() -> deg_barplot
deg_barplot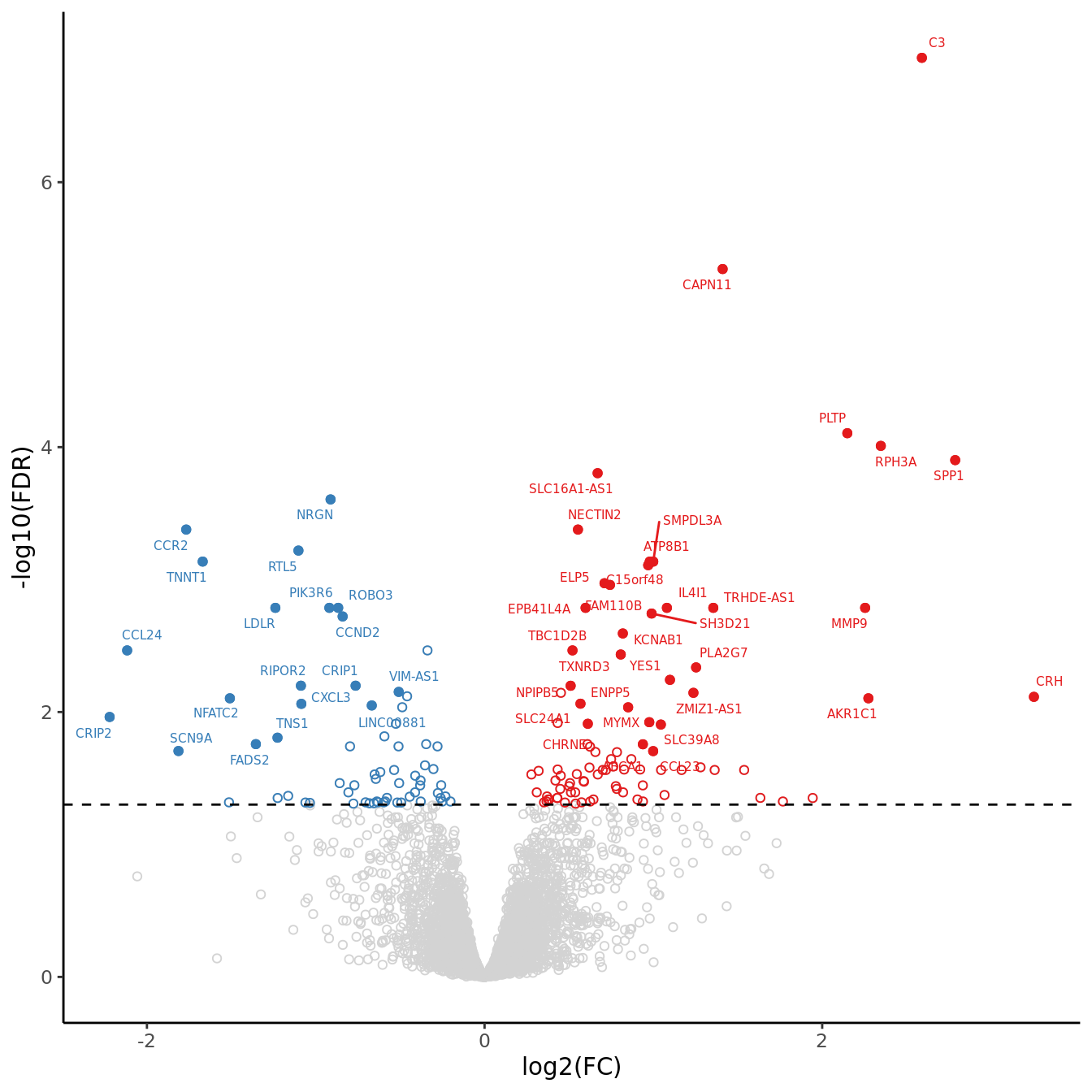
volc_plot <- draw_treat_volcano_plot(cell = "macrophages",
suffix = suffix,
cutoff = cutoff,
lfc_cutoff = lfc_cutoff)
volc_plot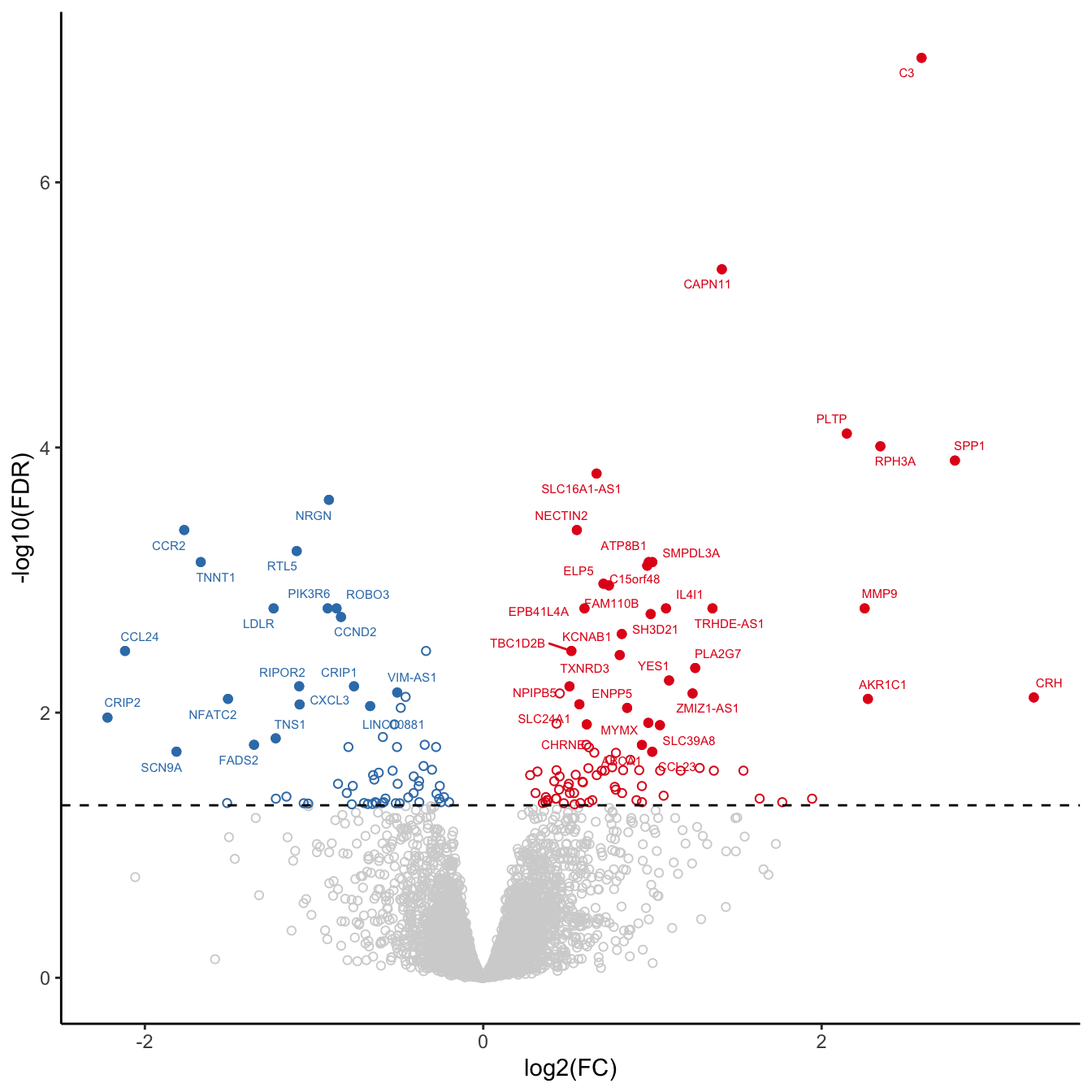
| Version | Author | Date |
|---|---|---|
| aa4438b | Jovana Maksimovic | 2025-09-10 |
Hs.c2.all <- convert_gmt_to_list(here("data/c2.all.v2024.1.Hs.entrez.gmt"))
Hs.h.all <- convert_gmt_to_list(here("data/h.all.v2024.1.Hs.entrez.gmt"))
Hs.c5.all <- convert_gmt_to_list(here("data/c5.all.v2024.1.Hs.entrez.gmt"))
fibrosis <- create_custom_gene_lists_from_file(here("data/fibrosis_gene_sets.csv"))
# add fibrosis sets from REACTOME and WIKIPATHWAYS
fibrosis <- c(lapply(fibrosis, function(l) l[!is.na(l)]),
Hs.c2.all[str_detect(names(Hs.c2.all), "FIBROSIS")])
gene_sets_list <- list(HALLMARK = Hs.h.all,
GO = Hs.c5.all,
REACTOME = Hs.c2.all[str_detect(names(Hs.c2.all), "REACTOME")],
WP = Hs.c2.all[str_detect(names(Hs.c2.all), "^WP")],
FIBROSIS = fibrosis)# alveolar macrophages, macro-CCL, macro-lipid, Monocyte-derived macrophages
cell_types <- c("macro-alveolar",
"macro-monocyte-derived")
# TNFA signalling by NFKB, inflammatory responses, MTORC1 signalling, and cholesterol homeostasis
selected <- "ALLOGRAFT_REJECTION|ANDROGEN_RESPONSE"
results_list <- lapply(cell_types, function(cell_type){
read_csv(file = here("output",
"dge_analysis",
cell_type,
"CAM.HALLMARK.CF.NO_MODvNON_CF.CTRL.csv")) %>%
dplyr::filter(!str_detect(Set, selected)) %>%
column_to_rownames(var = "Set") %>%
mutate(cell = cell_type)
})
names(results_list) <- rep("HALLMARK", length(results_list))
labels <- as_labeller(
c("HALLMARK; macro-alveolar" = "AM",
"HALLMARK; macro-monocyte-derived" = "Mac.Mono.Deriv"))
top_camera_sets_by_cell(results_list, num = 4, labeller = labels) +
theme(plot.title = element_blank(),
axis.text.y = element_text(size = 7,
angle = 0)) -> cam_plot_hallmark
cam_plot_hallmark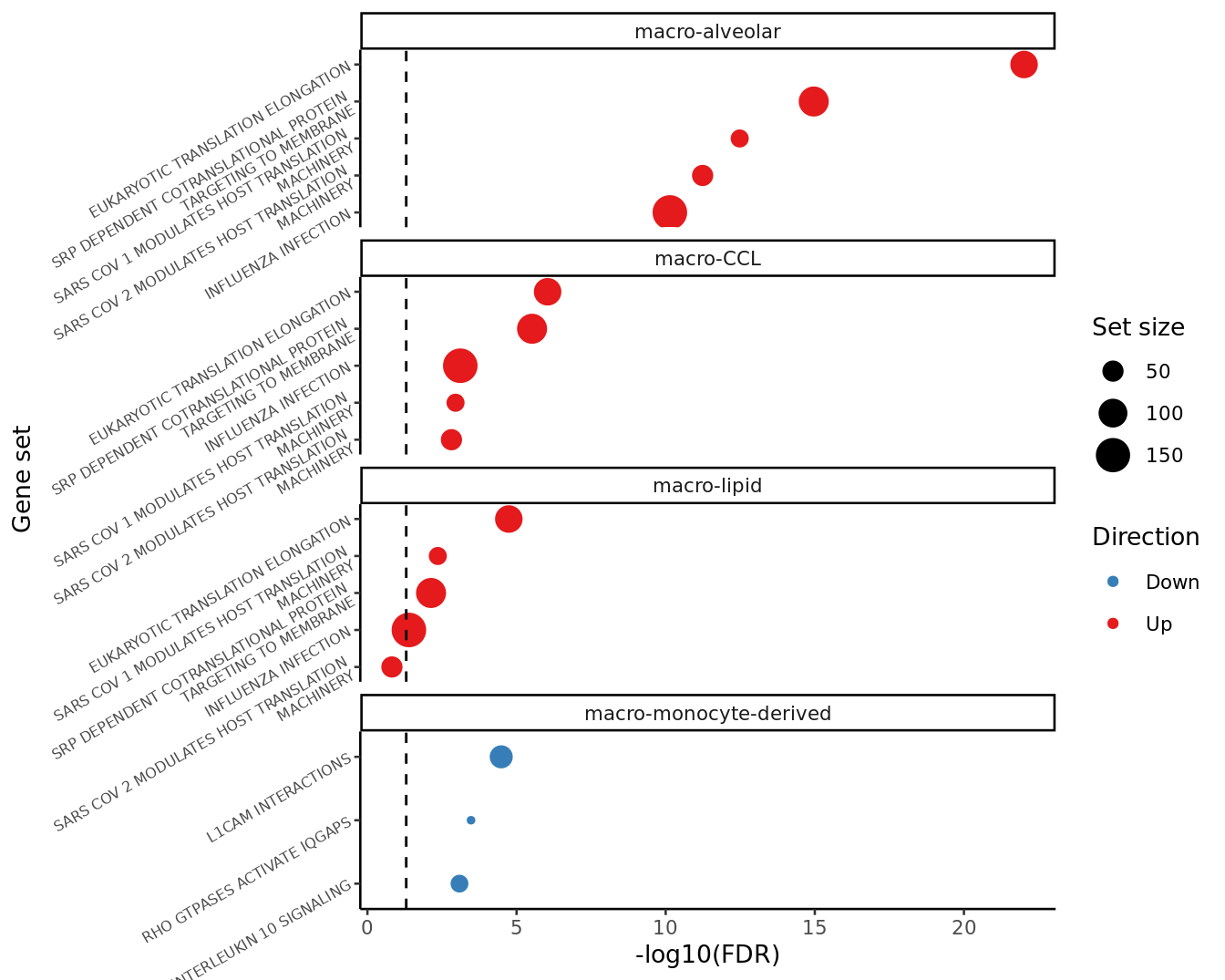
# alveolar macrophages, macro-CCL, macro-lipid, Monocyte-derived macrophages
cell_types <- c("macro-alveolar", "macro-CCL", "macro-lipid",
"macro-monocyte-derived")
# eukaryotic translation and elongation, SRP dependent cotranslational protein targeting to membrane, SARS-COV-1 and -2 host response and influenza infection
# L1CAM interactions, RHO GTPASES and IL-10 signalling
selected <- "EUKARYOTIC_TRANSLATION_ELONGATION|SRP_DEPENDENT_COTRANSLATIONAL|SARS_COV_1_MODULATES|SARS_COV_2_MODULATES|INFLUENZA_INFECTION|L1CAM_INTERACTIONS|INTERLEUKIN_10_SIGNALING|RHO_GTPASES_ACTIVATE_IQGAPS"
results_list <- lapply(cell_types, function(cell_type){
read_csv(file = here("output",
"dge_analysis",
cell_type,
"CAM.REACTOME.CF.NO_MODvNON_CF.CTRL.csv")) %>%
dplyr::filter(str_detect(Set, selected)) %>%
column_to_rownames(var = "Set") %>%
mutate(cell = cell_type)
})
names(results_list) <- rep("REACTOME", length(results_list))
labels <- as_labeller(
c("REACTOME; macro-alveolar" = "AM",
"REACTOME; macro-CCL" = "AM-CCL",
"REACTOME; macro-lipid" = "AM-lipid",
"REACTOME; macro-monocyte-derived" = "Mac.Mono.Deriv"))
top_camera_sets_by_cell(results_list, num = 5, wrap_width = 50,
labeller = labels) +
theme(plot.title = element_blank(),
axis.text.y = element_text(size = 6,
angle = 30)) -> cam_plot_reactome
cam_plot_reactome 
cell_types <- c("macrophages", "macro-alveolar")
fibrosis <- lapply(cell_types, function(cell_type){
read_csv(file = here("output",
"dge_analysis",
cell_type,
"ORA.FIBROSIS.CF.NO_MODvNON_CF.CTRL.csv")) %>%
column_to_rownames(var = "Set") %>%
mutate(cell = cell_type)
})
names(fibrosis) <- rep("FIBROSIS", length(fibrosis))
wp <- lapply(cell_types, function(cell_type){
read_csv(file = here("output",
"dge_analysis",
cell_type,
"ORA.WP.CF.NO_MODvNON_CF.CTRL.csv")) %>%
dplyr::filter(str_detect(Set, "PROFIBROTIC")) %>%
column_to_rownames(var = "Set") %>%
mutate(cell = cell_type)
})
names(wp) <- rep("WP", length(wp))
results_list <- c(fibrosis, wp)
labels <- as_labeller(
c("FIBROSIS; macro-alveolar" = "AM",
"WP; macro-alveolar" = "AM",
"FIBROSIS; macrophages" = "All Macs (exc. Prolif)",
"WP; macrophages" = "All Macs (exc. Prolif)"))
top_ora_sets_by_cell(results_list, num = 2, wrap_width = 30,
labeller = labels) +
theme(plot.title = element_blank(),
axis.text.y = element_text(size = 7,
angle = 0)) -> ora_plot_fibrosis
ora_plot_fibrosis 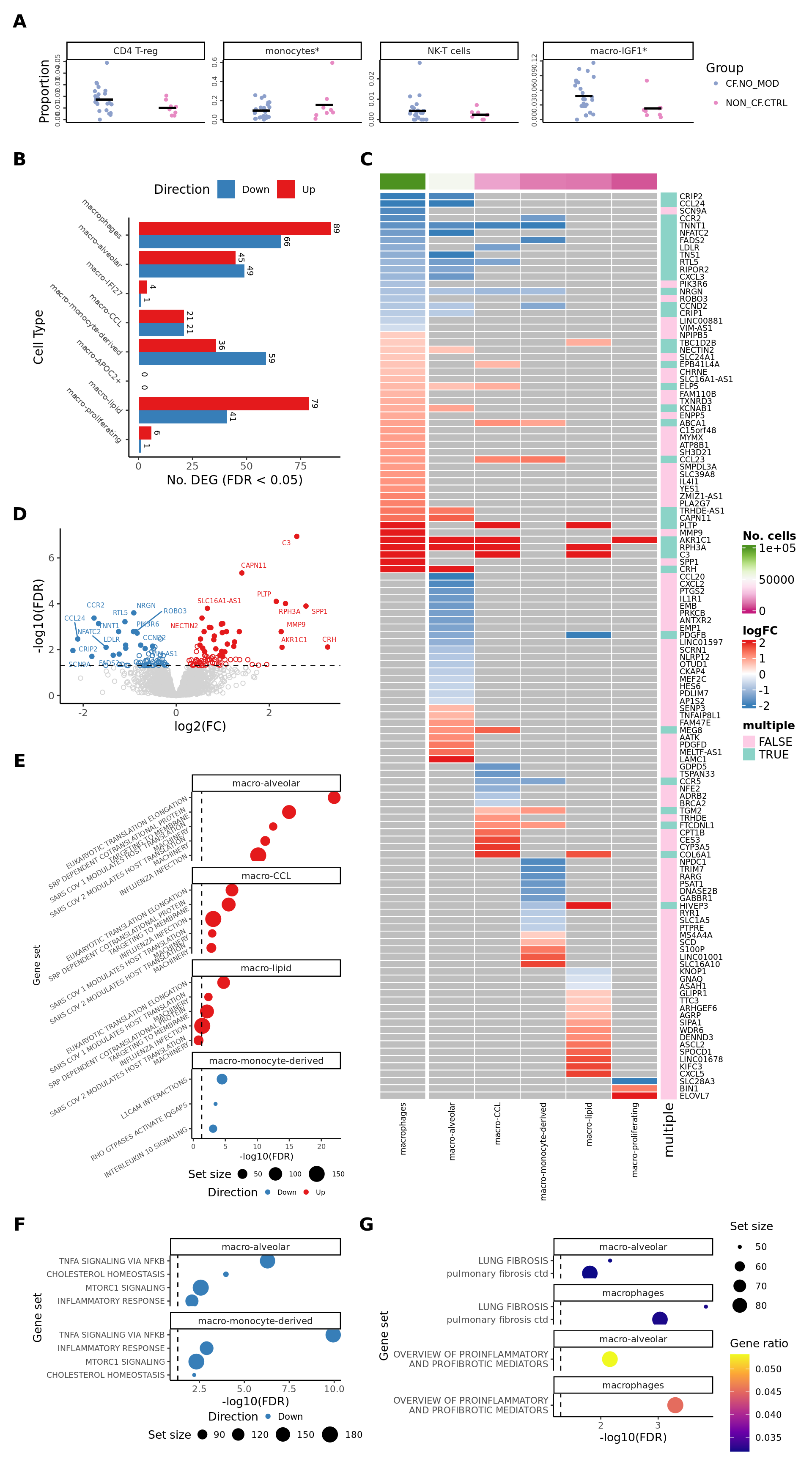
Figure 3
layout <- "
AAAAAAA
BBBCCCC
BBBCCCC
BBBCCCC
DDDCCCC
DDDCCCC
EEECCCC
EEECCCC
EEECCCC
EEECCCC
GGGHHHH
GGGHHHH
"
wrap_elements(cf_props & theme(legend.position = "right",
legend.direction = "vertical",
plot.margin = margin(rep(0,4)))) +
wrap_elements(deg_barplot + theme(plot.margin = margin(rep(0,4)),
axis.text.y = element_text(size = 8))) +
wrap_elements(grid::grid.grabExpr(ComplexHeatmap::draw(plot_lfc,
padding = unit(0, "mm")))) +
wrap_elements(volc_plot + theme(plot.margin = margin(rep(0,4)))) +
wrap_elements(cam_plot_reactome + theme(legend.position = "bottom",
legend.direction = "horizontal",
legend.box = "vertical",
legend.margin = margin(-0.5,0,0,0, unit="lines"),
legend.key.size = unit(0.5, unit="lines"),
legend.text = element_text(size = 6),
axis.title = element_text(size = 8),
axis.text = element_text(size = 6),
plot.margin = margin(rep(0,4)))) +
wrap_elements(cam_plot_hallmark + theme(legend.position = "bottom",
legend.direction = "horizontal",
legend.box = "vertical",
legend.margin = margin(-0.5,0,0,0, unit="lines"),
legend.key.size = unit(0.5, unit="lines"),
legend.text = element_text(size = 8),
axis.text = element_text(size = 8),
plot.margin = margin(rep(0,4)))) +
wrap_elements(ora_plot_fibrosis + theme(plot.margin = margin(rep(0,4)),
axis.text = element_text(size = 7))) +
plot_layout(design = layout) +
plot_annotation(tag_levels = "A") &
theme(plot.tag = element_text(size = 24,
face = "bold",
family = "arial")) -> p
p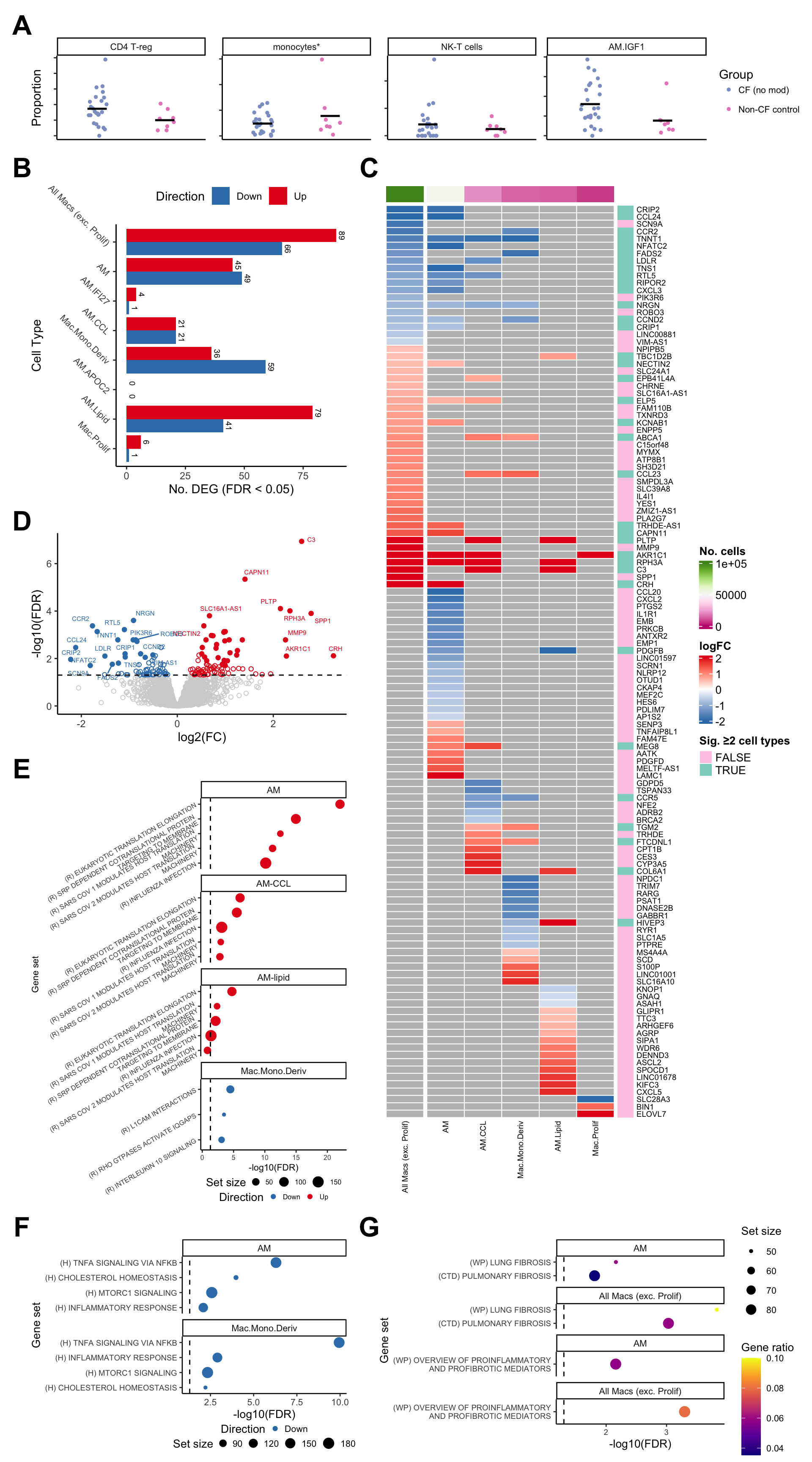
ggsave(here("output/pdf_figures/Figure_3.pdf"),
plot = p, width = 10, height = 19, units = "in", device = cairo_pdf)Supplement
library(ComplexHeatmap)
library(circlize)
library(msigdbr)
library(fgsea)
# ── Preparation function ───────────────────────────────────────────────────────
# Run once per cell type, returns all objects needed for plotting
deg_results <- lapply(files, function(f) readRDS(f))
prepare_tnfa <- function(idx, celltype_name, deg_results) {
lrt <- glmLRT(deg_results[[idx]]$fit, contrast = deg_results[[idx]]$contr[,1])
top <- topTags(lrt, n = Inf) %>% data.frame()
entrez <- mapIds(
org.Hs.eg.db,
keys = rownames(lrt),
column = "ENTREZID",
keytype = "SYMBOL",
multiVals = "first"
)
mat <- deg_results[[idx]]$adj$normalizedCounts %>% as.data.frame() %>% as.matrix()
mat_log <- log2(mat + 0.5)
mat_z <- t(scale(t(mat_log)))
metadata <- seu@meta.data
metadata[match(colnames(mat_z), metadata$sample.id), ] %>%
remove_rownames() %>%
dplyr::select(sample.id, Group, Treatment, Severity, Age) %>%
distinct() %>%
dplyr::filter(Treatment %in% c("Healthy", "untreated")) -> metadata_subset
sample_anno <- HeatmapAnnotation(
Severity = samp_map[metadata_subset$Severity],
Group = samp_map[metadata_subset$Group],
Age = metadata_subset$Age
)
tnfa_genes <- top[unname(entrez[rownames(top)]) %in%
gene_sets_list$HALLMARK$HALLMARK_TNFA_SIGNALING_VIA_NFKB, ] %>%
arrange(logFC)
ranked_genes <- top %>%
rownames_to_column(var = "gene") %>%
arrange(desc(logFC)) %>%
dplyr::select(gene, logFC) %>%
deframe()
hallmarks <- msigdbr(species = "Homo sapiens", category = "H") %>%
split(x = .$gene_symbol, f = .$gs_name)
set.seed(42)
gsea_res <- fgsea(pathways = hallmarks, stats = ranked_genes,
minSize = 15, maxSize = 500, nperm = 1000)
gsea_res_tidy <- gsea_res %>%
arrange(pval) %>%
#filter(padj < 0.05) %>%
slice_min(pval, n = 20) %>%
mutate(pathway = gsub("HALLMARK_", "", pathway))
tnfa_row <- gsea_res_tidy %>% filter(grepl("TNFA", pathway))
tnfa_genes_leading <- if (nrow(tnfa_row) > 0) unlist(tnfa_row[1, 8]) else NULL
tnfa_genes_min <- c("TNFAIP3", "NFKBIA", "TNF", "IL1B", "IL1A",
"CXCL2", "CXCL3", "NR4A1", "NR4A2")
list(
celltype_name = celltype_name,
lrt = lrt,
entrez = entrez,
mat_z = mat_z,
metadata_subset = metadata_subset,
sample_anno = sample_anno,
tnfa_genes = tnfa_genes,
tnfa_genes_min = tnfa_genes_min,
tnfa_genes_leading = tnfa_genes_leading,
gsea_res_tidy = gsea_res_tidy
)
}
# ── Plot functions ─────────────────────────────────────────────────────────────
plot_barcode <- function(obj) {
statistic <- sign(obj$lrt$table$logFC) * sqrt(obj$lrt$table$LR)
id <- ids2indices(
gene_sets_list$HALLMARK$HALLMARK_TNFA_SIGNALING_VIA_NFKB,
unname(obj$entrez[rownames(obj$lrt)])
)
barcodeplot(
statistics = statistic,
index = unlist(id),
main = glue("HALLMARK_TNFA_SIGNALING_VIA_NFKB — {obj$celltype_name}"),
xlab = glue("Signed LRT statistic (CF (no mod) - Non-CF (ctrl)) — {obj$celltype_name}")
)
}
plot_gsea <- function(obj) {
obj$gsea_res_tidy %>%
mutate(direction = ifelse(NES > 0, "Up", "Down")) %>%
ggplot(aes(x = -log10(padj), y = reorder(pathway, -log10(padj)),
size = abs(NES), colour = direction)) +
geom_point() +
scale_colour_manual(values = c("Up" = "#E41A1C", "Down" = "#377EB8"),
name = "Direction") +
scale_size_continuous(range = c(2, 8), name = "NES") +
geom_vline(xintercept = -log10(0.05), linetype = "dashed", colour = "grey50") +
labs(x = "-log10(adj. p-value)", y = NULL,
title = glue("GSEA — Hallmark gene sets — {obj$celltype_name}")) +
theme_bw() +
theme(axis.text.y = element_text(size = 8))
}
# gene_set: one of "full", "min", "leading"
# split: whether to split columns by Group
plot_tnfa_heatmap <- function(obj, gene_set = c("full", "min", "leading"), split = TRUE) {
gene_set <- match.arg(gene_set)
tnfa_subset <- switch(gene_set,
"full" = obj$tnfa_genes,
"min" = obj$tnfa_genes[rownames(obj$tnfa_genes) %in% obj$tnfa_genes_min, ],
"leading" = {
if (is.null(obj$tnfa_genes_leading)) {
message(glue("TNFa pathway not significant in {obj$celltype_name}"))
return(invisible(NULL))
}
obj$tnfa_genes[rownames(obj$tnfa_genes) %in% obj$tnfa_genes_leading, ]
}
)
label <- switch(gene_set,
"full" = "full TNFa gene set",
"min" = "min TNFa gene set",
"leading" = "leading edge TNFa genes"
)
row_anno <- rowAnnotation(
Significant = tnfa_subset$FDR < 0.05,
logFC = anno_barplot(tnfa_subset$logFC, gp = gpar(fill = "grey40"),
border = FALSE, width = unit(2, "cm"))
)
ht <- Heatmap(
obj$mat_z[rownames(tnfa_subset),
colnames(obj$mat_z) %in% unique(obj$metadata_subset$sample.id)],
name = "z-score",
col = colorRamp2(c(-2, 0, 2), c("blue", "white", "red")),
cluster_rows = FALSE,
cluster_columns = TRUE,
show_row_names = TRUE,
show_column_names = TRUE,
top_annotation = obj$sample_anno,
right_annotation = row_anno,
column_split = if (split) obj$metadata_subset$Group else NULL,
row_names_gp = gpar(fontsize = 8),
column_title = NULL
)
draw(ht, column_title = glue("{obj$celltype_name} — {label}"))
}am <- prepare_tnfa(idx = 1, celltype_name = "macro-alveolar", deg_results)
mono <- prepare_tnfa(idx = 6, celltype_name = "macro-monocyte-derived", deg_results)plot_barcode(am)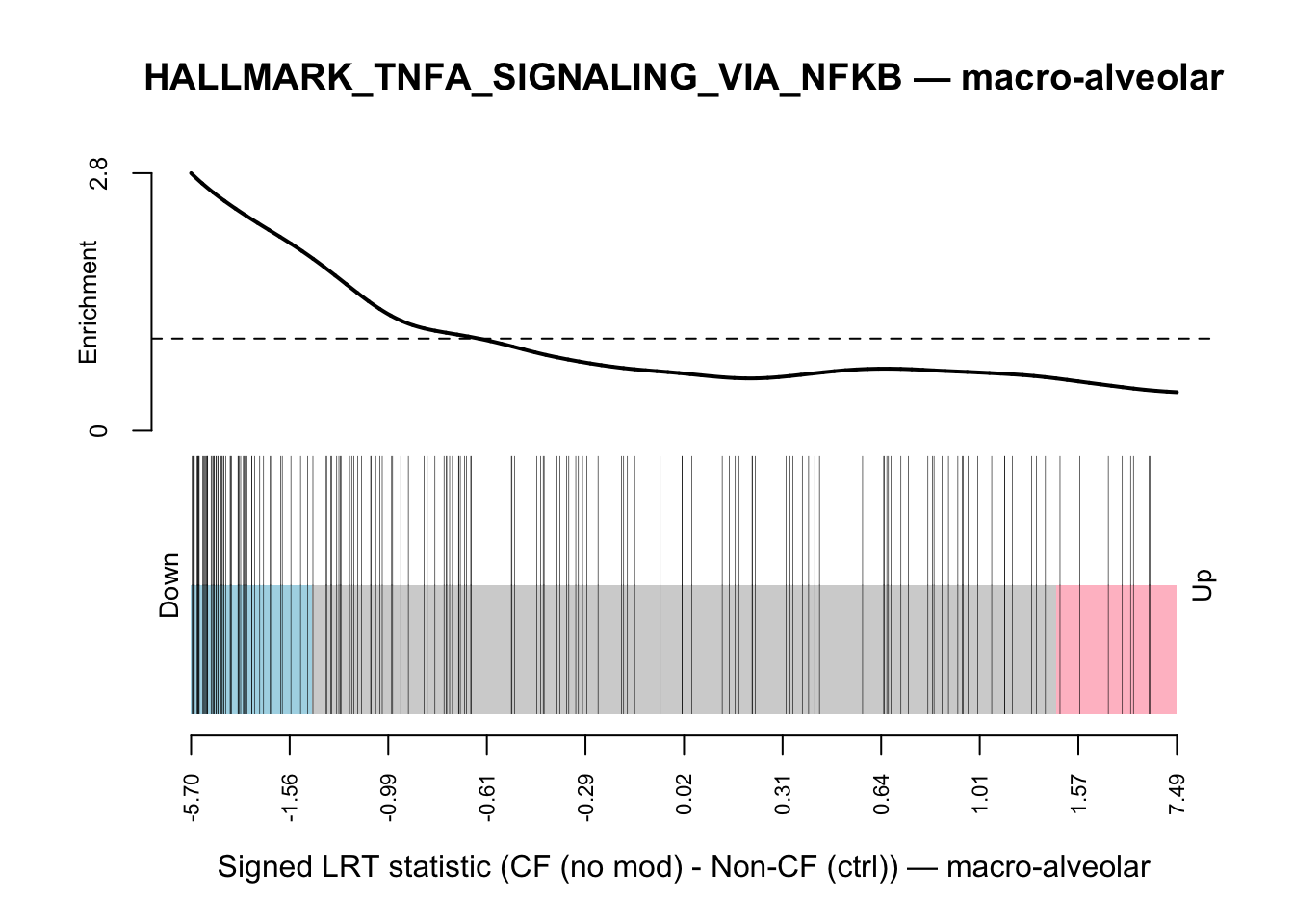
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_barcode(mono)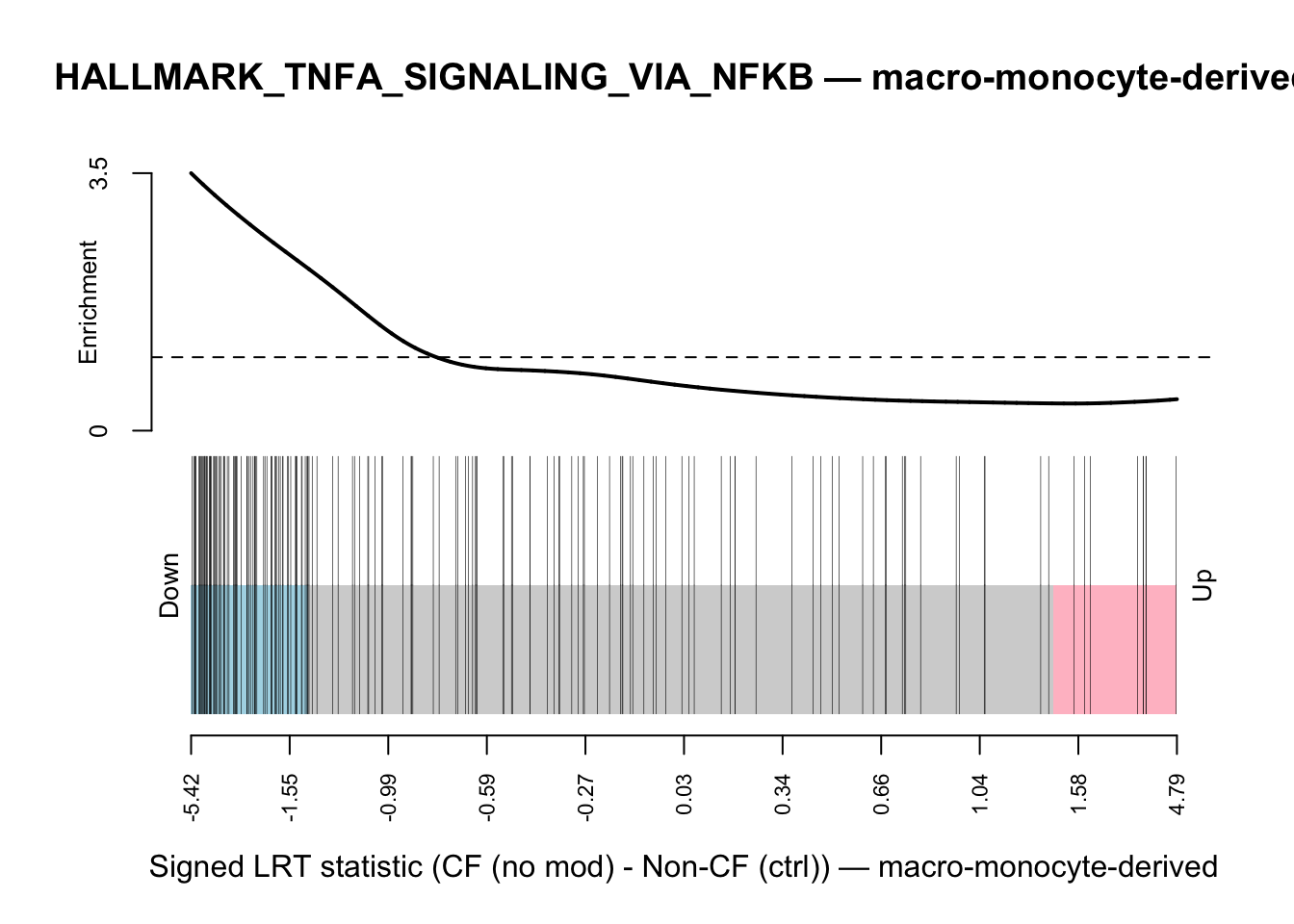
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_gsea(am)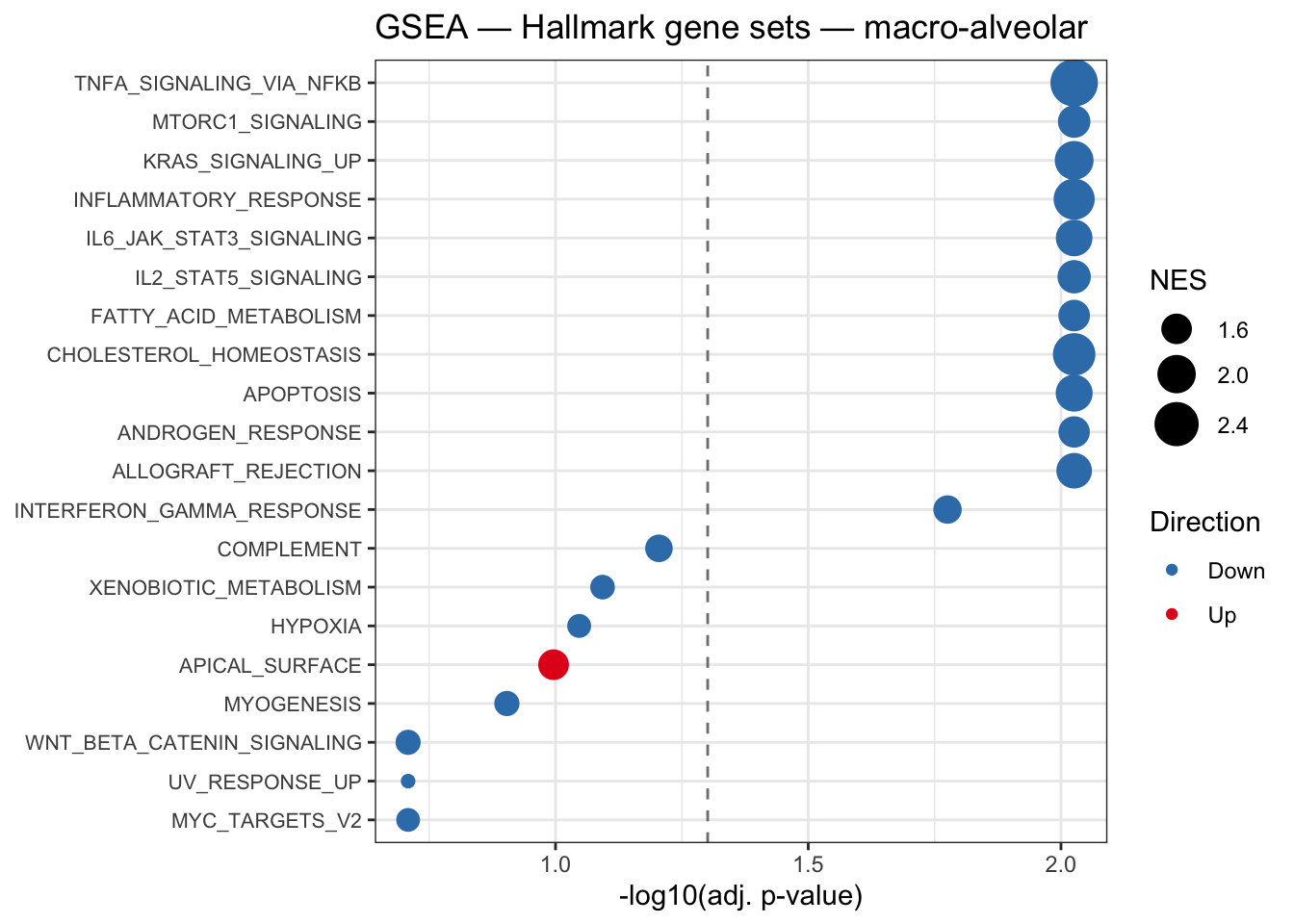
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_gsea(mono)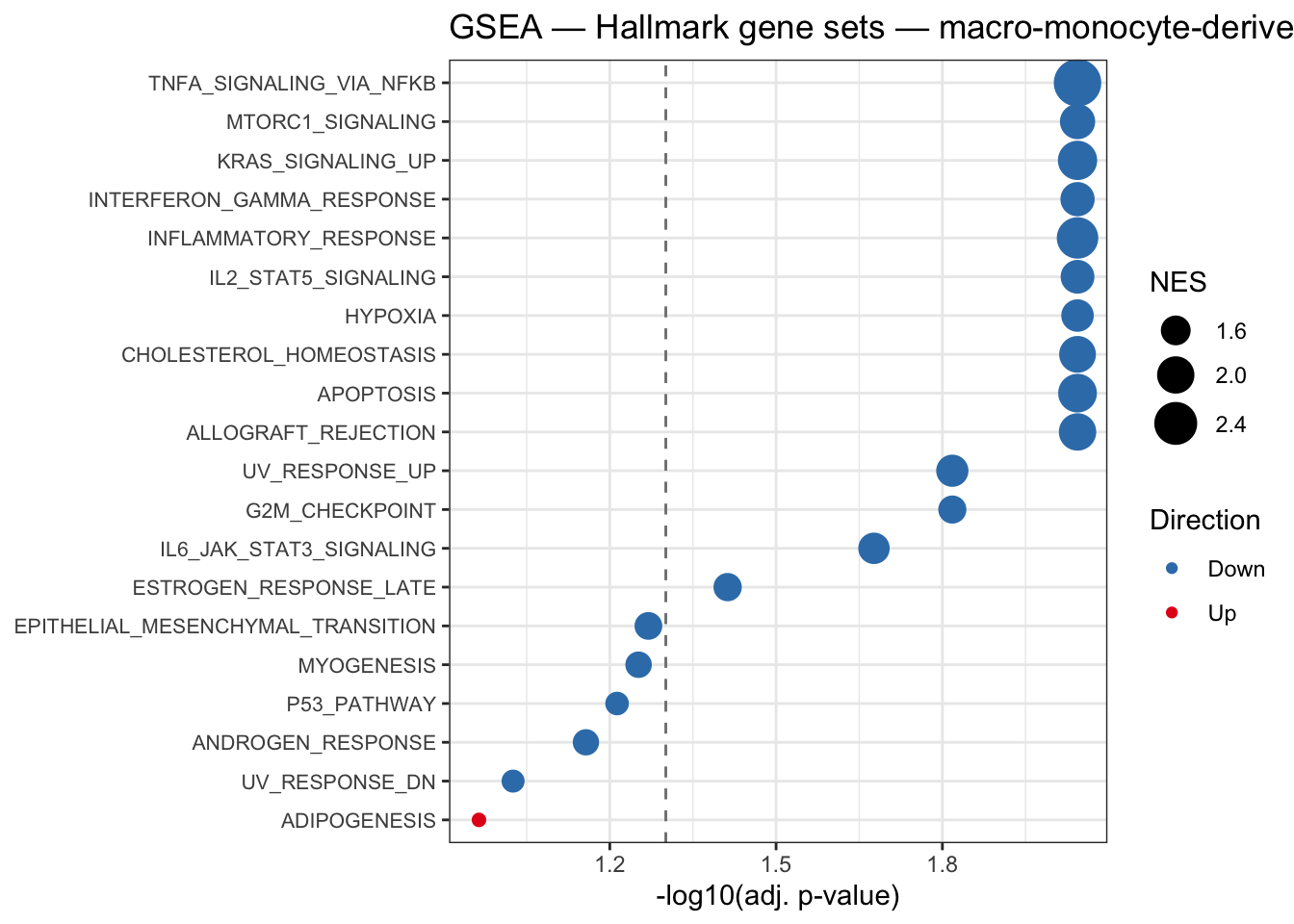
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_tnfa_heatmap(am, gene_set = "full", split = TRUE)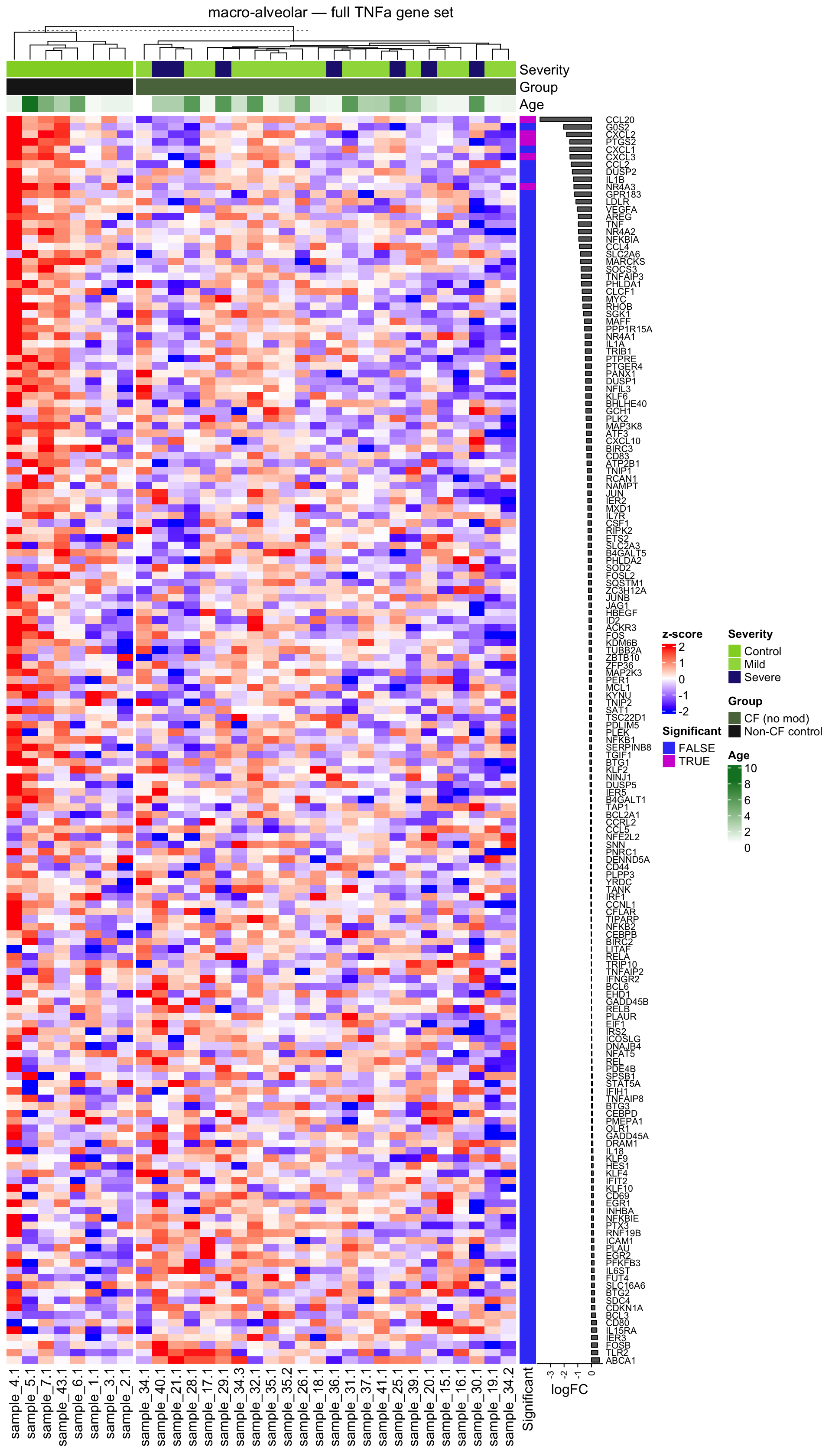
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_tnfa_heatmap(mono, gene_set = "full", split = TRUE)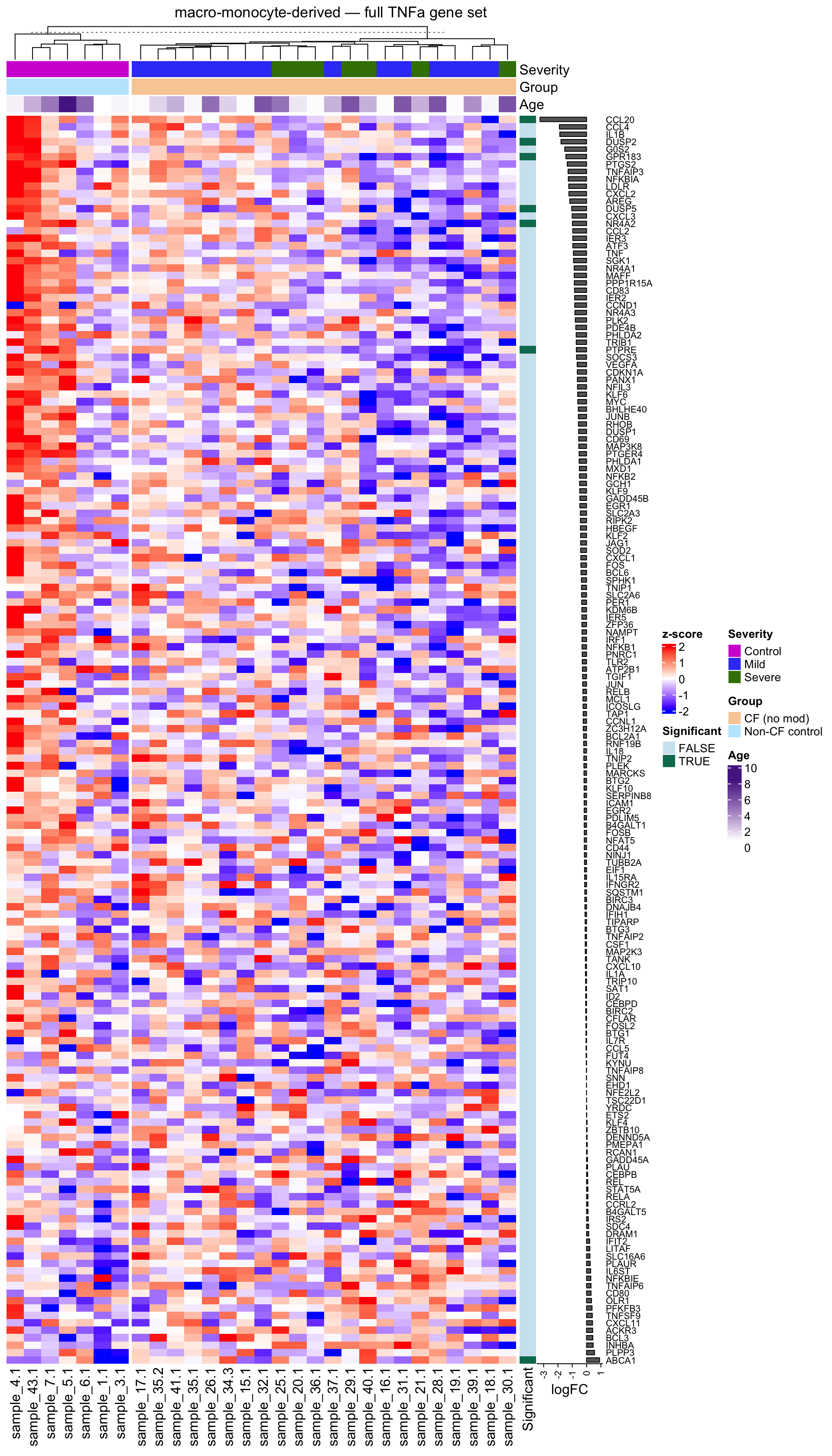
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_tnfa_heatmap(am, gene_set = "min")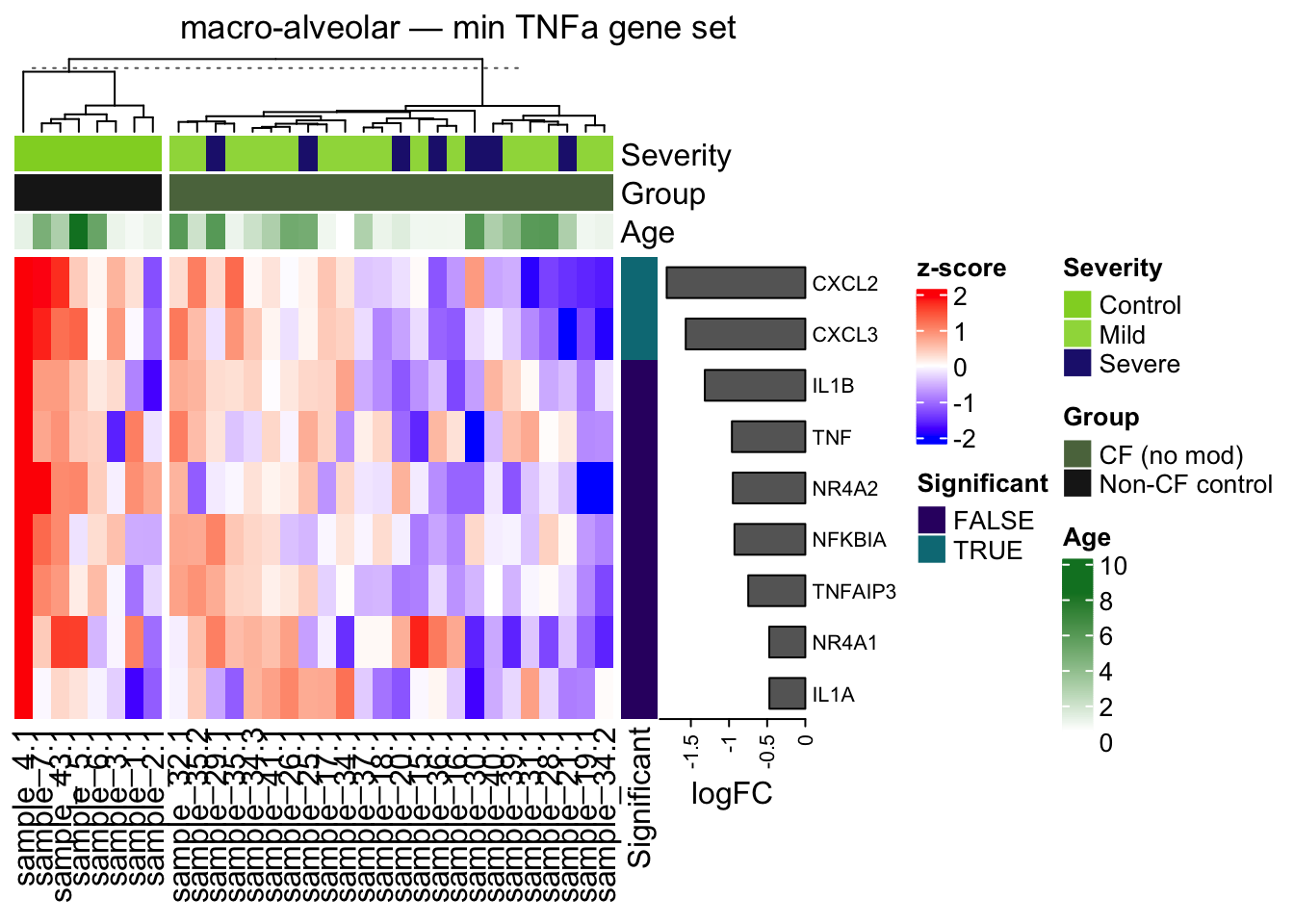
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_tnfa_heatmap(mono, gene_set = "min")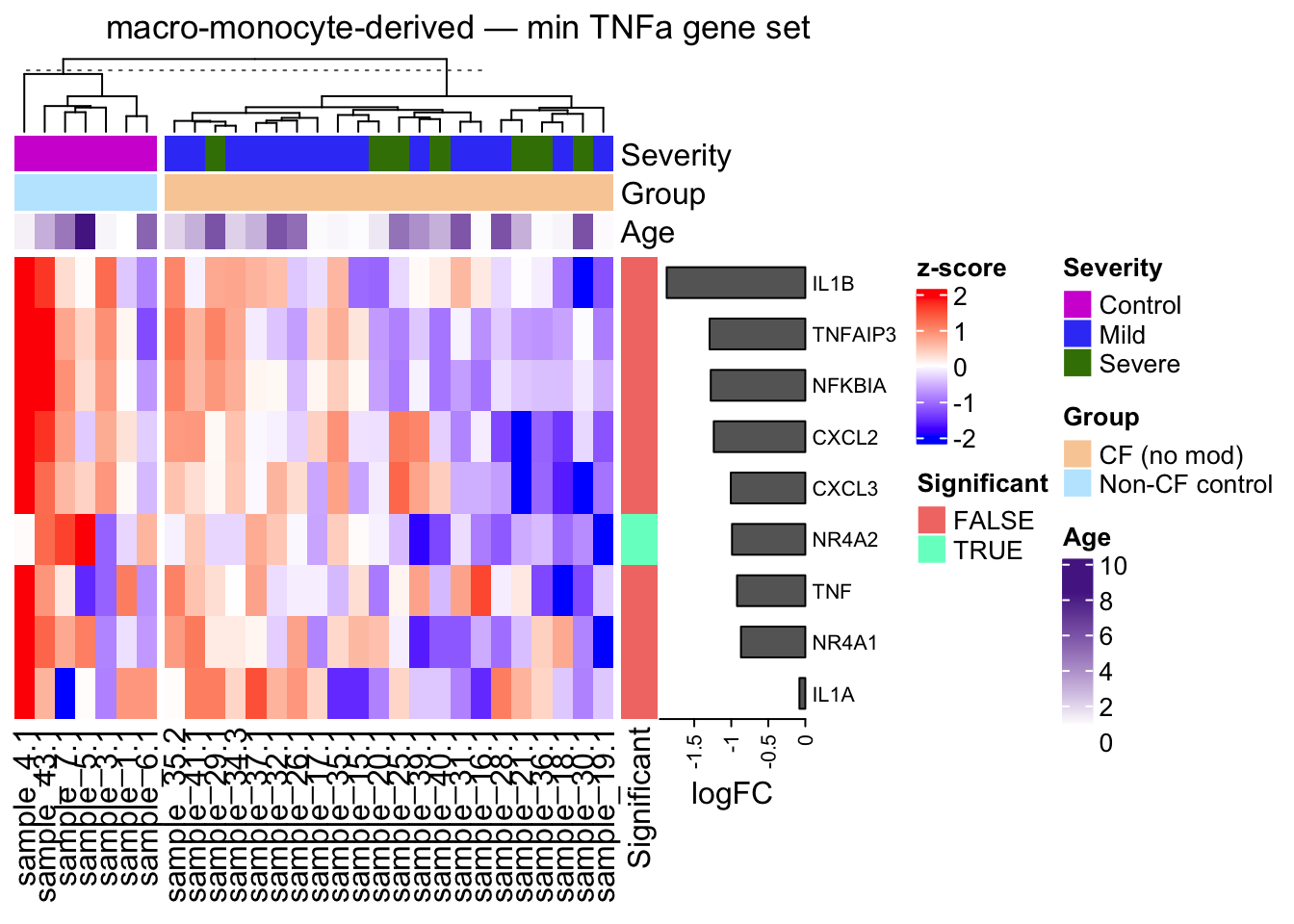
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_tnfa_heatmap(am, gene_set = "leading")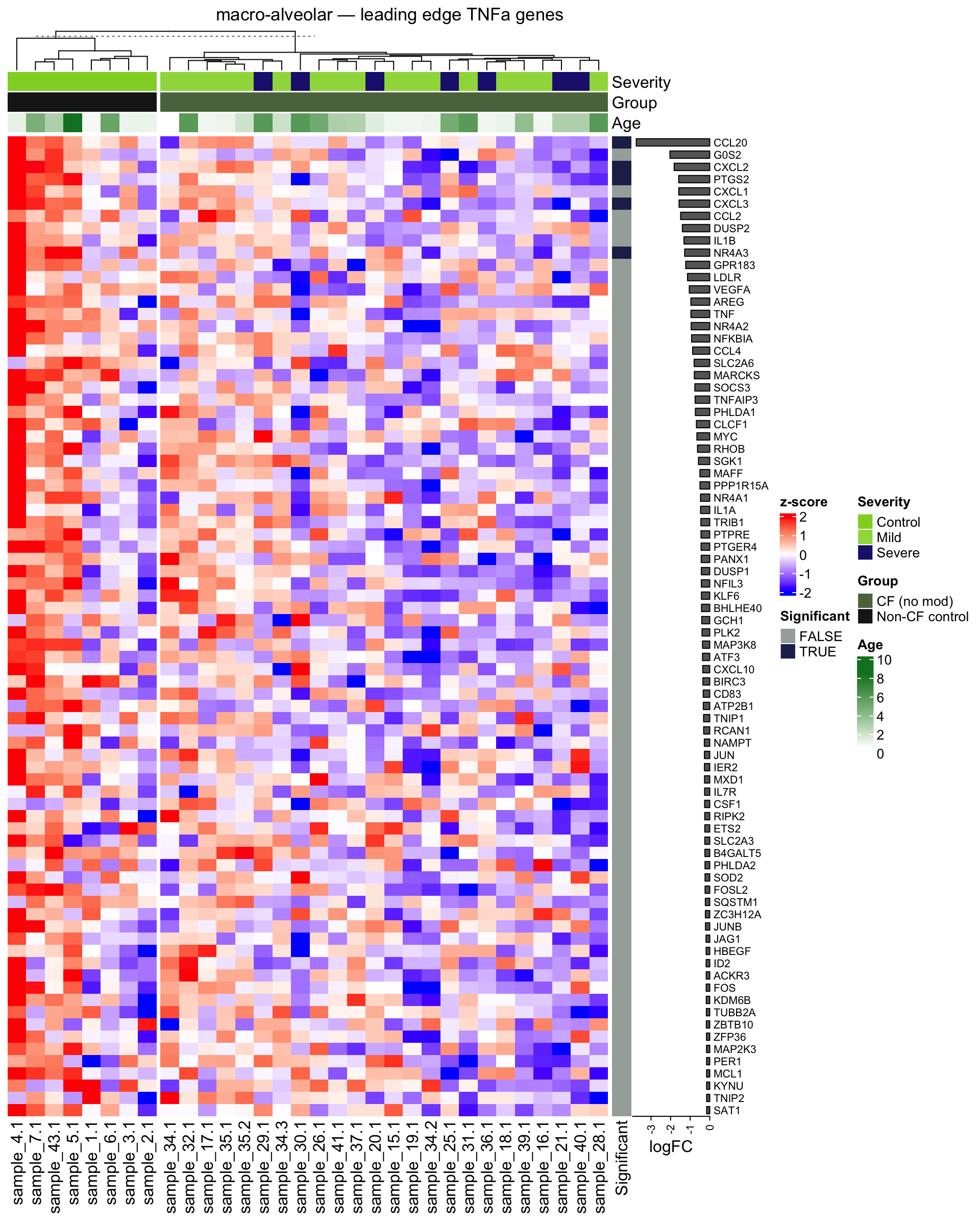
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
plot_tnfa_heatmap(mono, gene_set = "leading")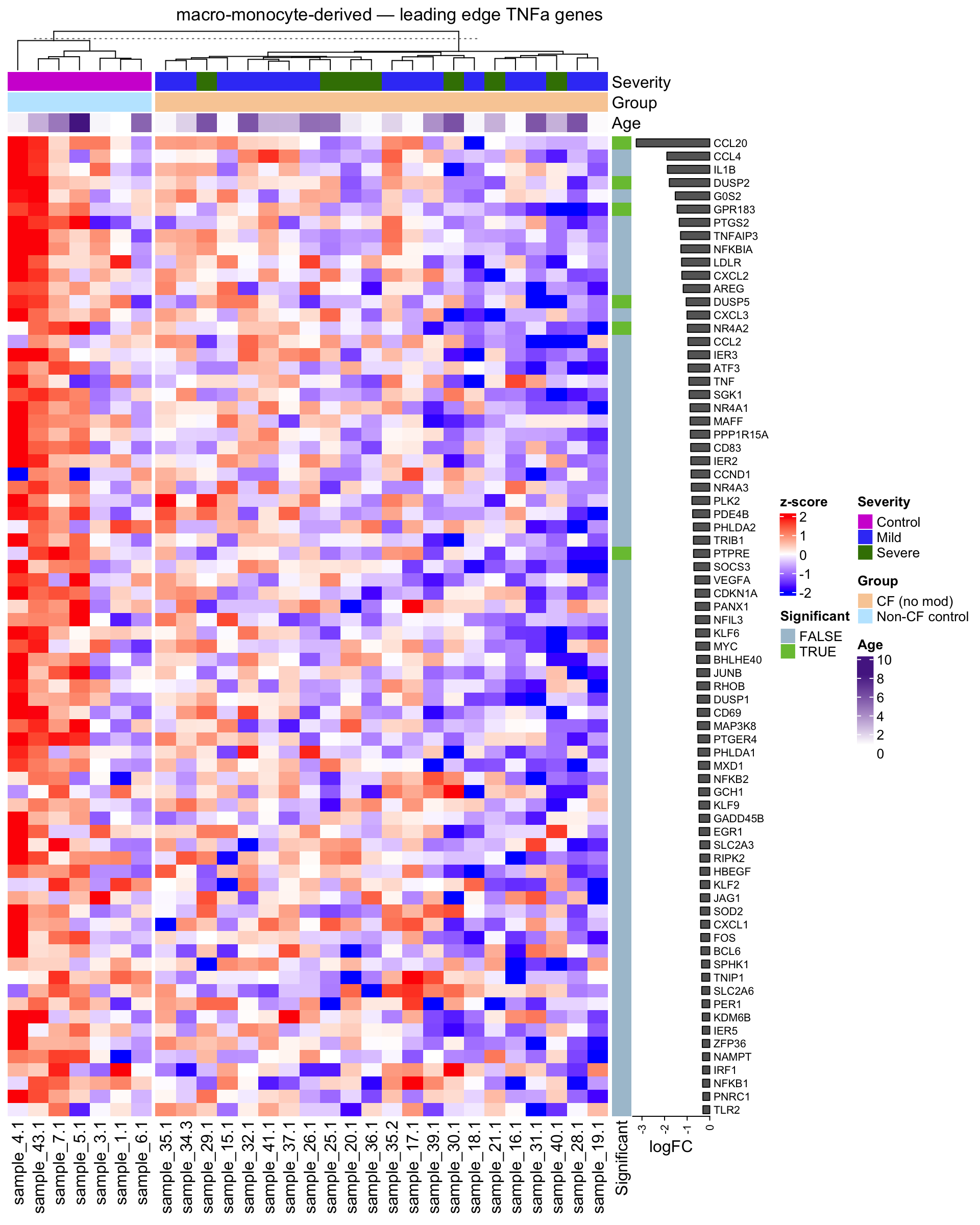
| Version | Author | Date |
|---|---|---|
| 91b42ff | Jovana Maksimovic | 2026-03-23 |
Session info
sessionInfo()R version 4.3.3 (2024-02-29)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS 15.5
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: Australia/Melbourne
tzcode source: internal
attached base packages:
[1] grid stats4 stats graphics grDevices datasets utils
[8] methods base
other attached packages:
[1] fgsea_1.28.0 msigdbr_26.1.0
[3] circlize_0.4.15 ComplexHeatmap_2.18.0
[5] readxl_1.4.3 ggh4x_0.3.1
[7] dsb_1.0.3 paletteer_1.6.0
[9] tidyHeatmap_1.8.1 speckle_1.2.0
[11] glue_1.8.0 org.Hs.eg.db_3.18.0
[13] AnnotationDbi_1.64.1 patchwork_1.3.1
[15] clustree_0.5.1 ggraph_2.2.0
[17] here_1.0.1 dittoSeq_1.14.2
[19] glmGamPoi_1.14.3 SeuratObject_4.1.4
[21] Seurat_4.4.0 lubridate_1.9.3
[23] forcats_1.0.0 stringr_1.5.1
[25] dplyr_1.1.4 purrr_1.0.2
[27] readr_2.1.5 tidyr_1.3.1
[29] tibble_3.2.1 ggplot2_3.5.2
[31] tidyverse_2.0.0 edgeR_4.0.15
[33] limma_3.58.1 SingleCellExperiment_1.24.0
[35] SummarizedExperiment_1.32.0 Biobase_2.62.0
[37] GenomicRanges_1.54.1 GenomeInfoDb_1.38.6
[39] IRanges_2.36.0 S4Vectors_0.40.2
[41] BiocGenerics_0.48.1 MatrixGenerics_1.14.0
[43] matrixStats_1.2.0 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] fs_1.6.6 spatstat.sparse_3.0-3 bitops_1.0-7
[4] httr_1.4.7 RColorBrewer_1.1-3 doParallel_1.0.17
[7] tools_4.3.3 sctransform_0.4.1 utf8_1.2.4
[10] R6_2.5.1 lazyeval_0.2.2 uwot_0.1.16
[13] GetoptLong_1.0.5 withr_3.0.0 sp_2.1-3
[16] gridExtra_2.3 progressr_0.14.0 cli_3.6.5
[19] Cairo_1.6-2 spatstat.explore_3.2-6 prismatic_1.1.1
[22] labeling_0.4.3 sass_0.4.10 spatstat.data_3.0-4
[25] ggridges_0.5.6 pbapply_1.7-2 parallelly_1.37.0
[28] rstudioapi_0.15.0 RSQLite_2.3.5 generics_0.1.3
[31] shape_1.4.6 vroom_1.6.5 ica_1.0-3
[34] spatstat.random_3.2-2 dendextend_1.17.1 Matrix_1.6-5
[37] fansi_1.0.6 abind_1.4-5 lifecycle_1.0.4
[40] whisker_0.4.1 yaml_2.3.8 snakecase_0.11.1
[43] SparseArray_1.2.4 Rtsne_0.17 blob_1.2.4
[46] promises_1.2.1 crayon_1.5.2 miniUI_0.1.1.1
[49] lattice_0.22-5 cowplot_1.1.3 KEGGREST_1.42.0
[52] pillar_1.9.0 knitr_1.50 rjson_0.2.21
[55] future.apply_1.11.1 codetools_0.2-19 fastmatch_1.1-8
[58] leiden_0.4.3.1 getPass_0.2-4 data.table_1.15.0
[61] vctrs_0.6.5 png_0.1-8 cellranger_1.1.0
[64] gtable_0.3.6 assertthat_0.2.1 rematch2_2.1.2
[67] cachem_1.0.8 xfun_0.52 S4Arrays_1.2.0
[70] mime_0.12 tidygraph_1.3.1 survival_3.5-8
[73] pheatmap_1.0.12 iterators_1.0.14 statmod_1.5.0
[76] ellipsis_0.3.2 fitdistrplus_1.1-11 ROCR_1.0-11
[79] nlme_3.1-164 bit64_4.0.5 RcppAnnoy_0.0.22
[82] rprojroot_2.0.4 bslib_0.6.1 irlba_2.3.5.1
[85] KernSmooth_2.23-22 colorspace_2.1-0 DBI_1.2.1
[88] tidyselect_1.2.1 processx_3.8.3 curl_5.2.0
[91] bit_4.0.5 compiler_4.3.3 git2r_0.33.0
[94] DelayedArray_0.28.0 plotly_4.10.4 scales_1.3.0
[97] lmtest_0.9-40 callr_3.7.3 digest_0.6.34
[100] goftest_1.2-3 spatstat.utils_3.0-4 rmarkdown_2.29
[103] XVector_0.42.0 htmltools_0.5.8.1 pkgconfig_2.0.3
[106] fastmap_1.1.1 rlang_1.1.6 GlobalOptions_0.1.2
[109] htmlwidgets_1.6.4 shiny_1.8.0 farver_2.1.1
[112] jquerylib_0.1.4 zoo_1.8-12 jsonlite_1.8.8
[115] BiocParallel_1.36.0 mclust_6.1 RCurl_1.98-1.14
[118] magrittr_2.0.3 GenomeInfoDbData_1.2.11 munsell_0.5.0
[121] Rcpp_1.0.12 babelgene_22.9 viridis_0.6.5
[124] reticulate_1.42.0 stringi_1.8.3 zlibbioc_1.48.0
[127] MASS_7.3-60.0.1 plyr_1.8.9 parallel_4.3.3
[130] listenv_0.9.1 ggrepel_0.9.5 deldir_2.0-2
[133] Biostrings_2.70.2 graphlayouts_1.1.0 splines_4.3.3
[136] tensor_1.5 hms_1.1.3 locfit_1.5-9.8
[139] ps_1.7.6 igraph_2.0.1.1 spatstat.geom_3.2-8
[142] reshape2_1.4.4 evaluate_0.23 renv_1.1.4
[145] BiocManager_1.30.22 tzdb_0.4.0 foreach_1.5.2
[148] tweenr_2.0.3 httpuv_1.6.14 RANN_2.6.1
[151] polyclip_1.10-6 future_1.33.1 clue_0.3-65
[154] scattermore_1.2 ggforce_0.4.2 janitor_2.2.0
[157] xtable_1.8-4 later_1.3.2 viridisLite_0.4.2
[160] memoise_2.0.1 cluster_2.1.6 timechange_0.3.0
[163] globals_0.16.2